
Рефераты по биологии
Рефераты по экономике
Рефераты по москвоведению
Рефераты по экологии
Краткое содержание произведений
Рефераты по физкультуре и спорту
Топики по английскому языку
Рефераты по математике
Рефераты по музыке
Остальные рефераты
Рефераты по авиации и космонавтике
Рефераты по административному праву
Рефераты по безопасности жизнедеятельности
Рефераты по арбитражному процессу
Рефераты по архитектуре
Рефераты по астрономии
Рефераты по банковскому делу
Рефераты по биржевому делу
Рефераты по ботанике и сельскому хозяйству
Рефераты по бухгалтерскому учету и аудиту
Рефераты по валютным отношениям
Рефераты по ветеринарии
Рефераты для военной кафедры
Рефераты по географии
Рефераты по геодезии
Рефераты по геологии
Реферат: Теория вероятностей
Реферат: Теория вероятностей
Вопрос 1
События и явления. Все события и явления реального мира разделяются на закономерные (детерминированные) и случайные (вероятностные).
Случайным событием называется такое событие, изменить или предсказать которое в процессе случайного явления невозможно. Случайное событие - это результат (исход) конкретной единичной реализации случайного явления. Так, выпадение чисел 1-6 при бросании игральной кости - случайное явление. Выпадение числа 6 в единичном испытании - случайное событие. Если оно может задаваться, то это уже не игральная кость, а инструмент шулера. Типовое обозначение случайных событий - крупными буквами алфавита (например, событие А - выпадение 1 при бросании кости, событие В - выпадение 2 и т.д.).
Классификация случайных событий. Событие называют достоверным (и обозначают индексом W), если оно однозначно и предсказуемо. Выпадение суммы чисел больше 1 и меньше 13 при бросании двух костей - достоверное событие. Событие является невозможным (и обозначается индексом Æ), если в данном явлении оно полностью исключено. Сумма чисел, равная 1 или большая 12 при бросании двух костей - события невозможные. События равновозможны, если шансы на их появление равны. Появление чисел 1-6 для игральной кости равновозможно.
Два события называются совместными, если появление одного из них не влияет и не исключает появление другого. Совместные события могут реализоваться одновременно, как, например, появление какого-либо числа на одной кости ни коим образом не влияет на появление чисел на другой кости. События несовместны, если в одном явлении или при одном испытании они не могут реализоваться одновременно и появление одного из них исключает появление другого (попадание в цель и промах несовместны).
1. Вероятность любого случайного события А является неотрицательной величиной, значение которой заключено в интервале от 0 до 1. 0 £ Р(А) £ 1.
2. Вероятность достоверного события равна 1. Р(W) = 1.
В общем случае событие W представляет собой сумму полной группы
возможных элементарных событий данного случайного явления: W=![]() wi. Следовательно, вероятность
реализации хотя бы одного случайного события из полной группы возможных событий
также равна 1, т.е. является событием достоверным.
wi. Следовательно, вероятность
реализации хотя бы одного случайного события из полной группы возможных событий
также равна 1, т.е. является событием достоверным.
Сумма противоположных событий
тоже составляет полную группу событий и соответственно вероятность суммы
противоположных событий равна 1:P(A+![]() )
= 1.
)
= 1.
Примером может служить бросание горсти монет. Орел или решка для каждой монеты – противоположные события. Сумма событий для горсти в целом равна 1 независимо от соотношения выпавших орлов и решек.
3. Вероятность невозможного события равна 0. Р(Æ) = 0.
|
Рис. 8.2.3. |
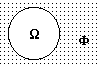
Пусть Ф - пустое пространство (не содержащее событий). Тогда W+Ф = W и пространство W не содержит событий, общих с пространством Ф (рис. 8.2.3). Отсюда следует, что Р(W+Ф) = Р(W) + Р(Ф) = Р(W), что выполняется при Р(Ф) = 0. Другими словами, если одно из событий обязательно должно происходить, то вероятность отсутствия событий должна быть равна нулю. Но при этом W является достоверным событием, а Ф = Æ (невозможное событие) и соответственно Р(Æ) = 0.
Вопрос 2
 Диаграмма
Вьенна-Эйлера
Диаграмма
Вьенна-Эйлера
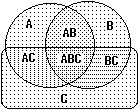
А) событие A
Б) Сложение – событие, кот состоит в том, что происходит хотя бы одно из событий A или B
В) произведение событий- А и B одновременно
Г) Дополнение – событие принадлежит к А, но не принадлежит к B
Д) противоположное событию A событие В
Е) Несовместимые события – если они не могут произойти одноременно
Ж) События образуют полную группу, если хотя бы одно из них обязательно происходит в результате испытания
З) А влечет за собой В
Вопрос 3
Классическая формула вероятности
Если множество элементарных событий Ω={ω1,ω2,…ωN},конечно и все элементарные события равновозможны, то такая вероятностная схема носит название классической. В этом случае вероятность Р{А} наступления события А, состоящего из М элементарных событий, входящих в Ω, определяется как отношение числа М элементарных событий, благоприятствующих наступлению события А, к общему числу N элементарных событий. Эта формула носит название классической формулы вероятности: Р{А}= M/N.
В частности, согласно классической формуле вероятности:
Р{ωi }=1/N (i=1,2,... , N)
Р{Ω}= N/N =1
P{Æ}=0/N =0
Комбинаторика, 1) то же, что математический
комбинаторный анализ. 2) Раздел элементарной математики, связанный с изучением
количества комбинаций, подчинённых тем или иным условиям, которые можно
составить из заданного конечного множества объектов (безразлично, какой
природы; это могут быть буквы, цифры, какие-либо предметы и т.п.). Число
размещений. Пусть имеется n различных предметов. Сколькими способами можно
выбрать из них т предметов (учитывая порядок, в котором выбираются предметы)?
Число способов равно Anm = ![]() ? Anm
называют числом размещений из n элементов по m. Число сочетаний. Пусть
имеется n различных предметов. Сколькими способами можно выбрать из них т
предметов (безразлично, в каком порядке выбираются предметы)? Число способов
такого выбора равно Cnm =
? Anm
называют числом размещений из n элементов по m. Число сочетаний. Пусть
имеется n различных предметов. Сколькими способами можно выбрать из них т
предметов (безразлично, в каком порядке выбираются предметы)? Число способов
такого выбора равно Cnm = ![]() Cnm
называют числом сочетаний из n элементов по m. Числа Cnm
получаются как коэффициенты разложения n-й степени двучлена: (a+b) n=Cn0
an +
Cn1 an-1b +Cn2an-2b2 ?+... + Cnn-1abn-1
+ Cnn bn, и поэтому они называются также
биномиальными коэффициентами. Основные соотношения для биномиальных
коэффициентов: Cnm=Cnn-m, Cnm?
+ Cnm+1 = Cn+1m+1, Cn0
+ Cn1 + Cn2 +...+ Cnn-1
+ Cnn =2n, ? Cn0 -
Cn1 + Cn2-...+ (-1) nCnn
= 0. Числа Anm, Pm и Cnm
связаны соотношением: Anm=Pm Cnm.
Рассматриваются также размещения с повторением (т. е. всевозможные наборы из m
предметов n различных видов, порядок в наборе существен) и сочетания с повторением
(то же, но порядок в наборе не существен). Число размещений с повторением
даётся формулой nm, число сочетаний с повторением - формулой Cmn+m-1.
Cnm
называют числом сочетаний из n элементов по m. Числа Cnm
получаются как коэффициенты разложения n-й степени двучлена: (a+b) n=Cn0
an +
Cn1 an-1b +Cn2an-2b2 ?+... + Cnn-1abn-1
+ Cnn bn, и поэтому они называются также
биномиальными коэффициентами. Основные соотношения для биномиальных
коэффициентов: Cnm=Cnn-m, Cnm?
+ Cnm+1 = Cn+1m+1, Cn0
+ Cn1 + Cn2 +...+ Cnn-1
+ Cnn =2n, ? Cn0 -
Cn1 + Cn2-...+ (-1) nCnn
= 0. Числа Anm, Pm и Cnm
связаны соотношением: Anm=Pm Cnm.
Рассматриваются также размещения с повторением (т. е. всевозможные наборы из m
предметов n различных видов, порядок в наборе существен) и сочетания с повторением
(то же, но порядок в наборе не существен). Число размещений с повторением
даётся формулой nm, число сочетаний с повторением - формулой Cmn+m-1.
Вопрос 4
При аксиоматическом построении вероятностей в каждом конкретном пространстве элементарных событий W выделяется s-поле событий S для каждого события AÎ S задается вероятность P{A} – числовая функция, определенная на s-поле событий S и удовлетворяющая следующим аксиомам.
Аксиома неотрицательности вероятности для всех A Î S: P{A}³ 0.
Аксиома нормированности вероятности: P{W}=1.
Аксиома адаптивности вероятности: для всех A,BÎS,таких, что AÇB¹Æ: P{AÈB}=P{A} +P{B}
Каждая определенная теоретико-вероятностная схема задается тройкой {W, S, P}, где W конкретное пространство элементарных событий, S - s-поле событий, выделенное на W, З – вероятность заданная на s-поле S. Тройка {W, S, P} называется вероятностным пространством
Пусть проводится конечное число n последовательных испытаний, в каждом из которых некоторое событие А может либо наступить (такую ситуацию назовём успехом),либо не наступить (такую ситуацию назовём неудаxей),причём эти испытания удовлетворяют следующим условиям:
1)каждое испытание случайно относительно события А, т.е. до проведения испытания нельзя сказать появится А или нет;
2)испытания проводятся в одинаковых с вероятностной точки зрения условиях, т.е. вероятность успеха в каждом отдельно взятом испытании равна р и не меняется от испытания к испытанию;
3)испытания независимы, т.е. исход любого из них никак не влияет на исходы других испытаний.
Такая последовательность испытаний называется схемой Бернулли или биноминальной схемой, а сами испытания- испытаниями Бернулли.
Ф-ла Бернулли: Рmn = Cmn* pm * q n-m = Cmn* pm * (1-p) n-m
Cmn= n!/ m!(n-m)!
Вопрос 5
Сложение вероятностей зависит от совместности и несовместности событий.
Несовместные события. Вероятность суммы двух несовместных событий А и В равна сумме вероятностей этих событий. Это вытекает из того, что множество С = А+В включает подмножества А и В, не имеющие общих точек, и Р(А+В) = Р(А)+Р(В) по определению вероятности на основе меры. По частотному определению вероятности в силу несовместности событий имеем:
P(A+B) = ![]() =
=
![]() +
+![]() =
P(A) + P(B),
=
P(A) + P(B),
где n и m - число случаев появления событий А и В соответственно при N испытаниях.
Противоположные
события также являются несовместными и образуют полную группу. Отсюда, с учетом:
P(![]() ) = 1 - Р(А).
) = 1 - Р(А).
|
Рис. 8.2.4. |
В общем случае для группы несовместных событий: P(A+B+...+N) = P(A) + P(B) + ... + P(N),
если все подмножества принадлежат одному множеству событий и не имеют общих точек (попарно несовместны). А если эти подмножества образуют полную группу событий, то с учетом: P(A) + P(B) + ... + P(N) = 1. (8.2.7)
|
Рис. 8.2.5. |
Совместные события. Вероятность появления хотя бы одного из двух совместных событий равна сумме вероятностей этих событий без вероятности их совместного появления : P(A+B) = P(A) + P(B) - P(A×B).
Разобьем события А и В каждое на два множества, не имеющие общих точек: А', A'' и B', B''. Во множества А'' и B'' выделим события, появляющиеся одновременно, и объединим эти множества в одно множество С. Для этих множеств действительны выражения:
С = A''×B'' º А'' º В'' º А×В, P(C) = P(A'') = P(B'') = P(A×B).
P(A) = P(A')+P(A''), P(A') = P(A)-P(A'') = P(A)-P(A×B).
P(B) = P(B')+P(B''), P(B') = P(B)-P(B'') = P(B)-P(A×B).
Множества A', B' и С не имеют общих точек и можно записать:
P(A+B) = P(A'+B'+C) = P(A') + P(B') + P(С).
Подставляя в правую часть этого уравнения вышеприведенные выражения, приходим к выражению (8.2.8). Физическая сущность выражения достаточно очевидна: суммируются вероятности событий А и В и вычитаются вероятности совпадающих событий, которые при суммировании сосчитаны дважды.
В общем случае, для m различных событий А1, А2, ..., Аm:
P(A1+...+
Am) =![]() P(Ai) -
P(Ai) -![]() P(Ai×Aj) +
P(Ai×Aj) +![]() P(Ai×Aj×Ak) -...+(-1)m+1P(A1×A2× ... ×Am).
(8.2.9)
P(Ai×Aj×Ak) -...+(-1)m+1P(A1×A2× ... ×Am).
(8.2.9)
|
Рис. 8.2.6. |
На рис. 8.2.6 на примере трех пространств можно видеть причины появления в выражении (8.2.9) дополнительных сумм вероятностей совпадающих пространств и их знакопеременности. При суммировании вероятностей пространств А,В и С, имеющих общее пространство АВС, его вероятность суммируется трижды, а при вычитании вероятностей перекрывающихся подпространств АВ, АС и ВС трижды вычитается (т.е. обнуляется), и восстанавливается дополнительным суммированием с вероятностью пространства АВС.
Вопрос 6
1) Условная вероятность события А при условии В равна Р(А/B)=P(A*B)/P(B), Р(В)>0.
2) Событие А не зависит от события В, если Р(А/B)=P(A). Независимость событий взаимна, т.е. если событие А не зависит от В, то событие В не зависит от А. В самом деле при Р(А)>0 имеем Р(B/A)=P(A*B)/P(A)=P(A/B)*P(B)/P(A)=P(A)*P(B)/P(A)=P(B). Вытекает следующая формула умножения вероятностей: Р(А*В)=Р(А)*Р(В/A). Для независимых событий вероятность произведения событий равна произведению их вероятностей: Р(А*В)=Р(А)*Р(В). 3) События А1,А2,…,Аn образуют полную группу событий, если они попарно несовместны и вместе образуют достоверное событие, т.е. Аi*Aj=0, i не=j, U по i от 1 до n Аi=омега.
Вероятность совместного появления двух событий равна произведению вероятности одного из них на условную вероятность другого, вычисленную в предположении, что первое событие уже наступило: Р(АВ)=Р(А)*Ра(В). В частности для независимых событий Р(АВ)=Р(А)*Р(В), т.е. вероятность совместного появления двух независимых событий равна произведению вероятностей этих событий.
Вопрос 7
Формула полной вероятности. Систему событий А1, А2, ...,AN называют конечным разбиением (или просто разбиением), если они попарно несовместны, а их сумма образует полное пространство событий: А1 + А2 + ... + АN = W.
Если события Аi
образуют разбиение пространства событий и все P(Ai) > 0, то для любого события В имеет место формула
полной вероятности: P(B) =![]() P(Ak)×P(B/Ak),
P(Ak)×P(B/Ak),
что непосредственно следует из (8.2.14) для попарно несовместных событий:
B = B×W = BA1+BA2+...BAN.
P(B) = P(BA1)+P(BA2)+... +P(BAN) = P(A1)P(B/A1)+P(A2)P(B/A2)+...+P(AN)P(B/AN).
Вопрос 8

Вопрос 9

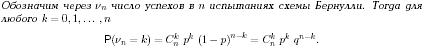
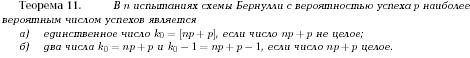
Вопрос 10
Случайной величиной называется числовая величина, которая в результате опыта может принять какое-либо значение из некоторого множества, причем заранее, до проведения опыта, невозможно сказать, какое именно значение она примет. Случайные величины обозначают заглавными латинскими буквами X, Y, Z,..., а их возможные значения — строчными латинскими буквами х, у, z. Случайная величина называется дискретной, если множество ее значений конечно или счетно, и непрерывной в противном случае. Законом распределения случайной величины называется любое соотношение, связывающее возможные значения этой случайной величины и соответствующие им вероятности. Закон распределения дискретной случайной величины задается чаще всего не функцией распределения, а рядом распределения, т.е, таблицей
|
Х |
x1 |
x2 |
... |
xn |
... |
|
P |
p1 |
p1 |
... |
pn |
... |
В которой x1, x2, ..., xn, ... - расположенные по возрастанию значения дискретной случайной величины X, а р1, р2, ..., рп, ... — отвечающие этим значениям вероятности: pi = Р{Х = хi), i= 1, 2, ..., п, ... . Число столбцов в этой таблице может быть конечным (если соответствующая случайная величина принимает конечное число значений) или бесконечныи. Очевидно,S pi= 1.
Многоугольником распределения дискретной случайной величины X называется ломаная, соединяющая точки {xi; pi), расположенные в Порядке возрастания хi.
Вопрос 11
Функцией распределения случайной величины Х называется функция FX(x)= P{X<x}, xÎR
Под {X<x}понимается событие, состоящее в том, что случайная величина Х принимает значение меньшее, чем число х. Если известно, о какой случайной величине идёт речь, то индекс, обозначающий эту случайную величину, опускается: F(x) º FX(x).
Как числовая функция от числового аргумента х, функция распределения F(x) произвольной случайной величины Х обладает следующими свойствами:
1)для любого xÎR: 0£ F(x) £ 1
2) F(-¥) = limx®¥ F(x) = 0 ; F(+¥) = limx®¥ F(x) = 1;
3) F(x)-неубывающая функция, т.е.для любых х1,х2 ÎR таких, что х1<х2: F(x1) £ F(x2);
4)для любого xÎR: F(x)= F(x-0)= lim z<x,z®xF(z).
Вопрос 12
Мат. Ожиданием Д.С.В. называют сумму произведений всех ее возможных значений на их вероятности: М(Х)=х1р1+х2р2+…+хnpn. Если Д.С.В. принимает счетное множество возможных значений, то М(Х)=сумма по i от 1 до бесконечности xipi, причем мат. ожидание существует, если ряд в правой части равенства сходится абсолютно. Мат. ожидание обладает следующими свойствами: 1) Мат. ожидание постоянной величины равно самой постоянной: М(С)=С. 2) Постоянный множитель можно выносить за знак мат. ожидания: М (СХ)=СМ (Х). 3) Мат. ожидание произведения взаимно независимых С.В. равно произведению мат. ожиданий сомножителей: М (Х1,Х2…Хn)=M(X1)*M(X2)…M(Xn). 4) Мат. ожидание суммы С.В. равно сумме мат. ожиданий слагаемых: М (Х1+Х2+Х3+…+Хn)=M(X1)+M(X2)+M(X3)+…+M(Xn).
Вопрос13
Дисперсией случайной величины х называется число: DX= M(X-MX)2 ,равное математическому ожиданию квадрата отклонения случайной величины от своего математического ожидания. Для вычисления дисперсии иногда проще использовать формулу: DX=M(X2)-(MX)2 . Для дискретных св:
DX=∑(xi – MX)2 pi;
DX=∑xi2pi – (MX) 2.
Свойства дисперсии дискретной случайной величины: (X,Y-независимые д.св, с- неслучайная постоянная ÎR)
Dc=0;
D(cX)=c2DX;
D(X+Y)= DX + DY
Вопрос 14
Биномиальным называют закон распределения Д.С.В. Х - числа появлений события в n независимых испытаниях, в каждом из которых вероятность появления события равна р, вер-ть возможного значения Х=k (числа k появлений события) вычисляют по формуле Бернулли: Pn (k)=Cn^k* p^k *q^(n-k)
Вопрос 15
Случайная величина Х наз.распределённой по геометрическому закону с параметром р (рÎ[0;1]), если она принимает значения 1,2,3… с вероятностями Р{Х=х}= р(1-р)х-1 (х = 1,2,3…).
Случайную величину Х можно интерпритировать как число испытаний Бернулли, которые придётся произвести до первого успеха, если успех в единичном испытании может произойти с вероятностью р.
Математическое ожидание случайной величины, имеющей геометрическое распределение: МХ=1/p.
Дисперсия: DX=1-p/p2
Вопрос 16
Если число испытаний велико, а вероятность P повяления события в каждом испытнаии очень мала, то используют приближенную формулу
Pn(k)=l^k*e^(-l/k)
Где k – число появлений события в n независимых испытаниях, l = np (среднее число появлений события в n независимых испытаниях), и говорят, что случайная величина распределена по закону Пуассона.
Вопрос 17
С.В. Х называется непрерывной, если существует неотрицательная функция рх(х) такая, что при любых х функцию распределения Fx(x) можно представить в виде: Fx(x)=интеграл от –бесконечности до х px(y)dy. Рассматривают только такие С.В., для которых рх(х) непрерывна всюду, кроме, может быть, конечного числа точек. Плотностью распределения вероятностей непрерывной С.В. называют первую производную от функции распределения: f(x)=F’(x). Вероятность того, что Н.С.В. Х примет значение, принадлежащее интервалу (а,b), определяется равенством P(a<X<b)=интервал от а до b f(x)dx. Зная плотность распределения можно найти функцию распределения F(x)=интеграл от –бесконечности до х f(x)dx. Плотность распределения обладает следующими свойствами: 1) П.Р. неотрицательна, т.е. f(x)>=0. 2) Несобственный интеграл от плотности распределения в пределах от –бесконечности до бесконечности равен единице: интеграл от –бесконечности до бесконечности f(x)dx=1.
Вопрос 18
Мат. ожидание Н.С.В. Х, возможные значения которой принадлежат всей оси ОХ, определяется равенством: М(Х)=интеграл от –бесконечности до бесконечности хf(x)dx, где f(x) - плотность распределения С.В. Х. Предполагается, что интеграл сходится абсолютно. В частности, если все возможные значения принадлежат интервалу (а,b), то М(Х)=интеграл от а до b xf(x)dx. Все свойства мат. ожидания, указаны выше, для Д.С.В. Они сохраняются и для Н.С.В.
Дисперсия Н.С.В. Х, возможные значения которой принадлежат всей оси ОХ, определяется равенством: D(X)=интеграл от –бесконечности до бесконечности [x-M(X)]*2f(x)dx, или равносильным равенством: D(X)=интеграл от –бесконечности до бесконечности x*2f(x)dx – [M(X)]*2. В частности, если все возможные значения х принадлежат интервалу (a,b),то D(X)=интервал от а до b [x – M(X)]*2f(x)dx,или D(X)=интеграл от a до b x*2f(x)dx – [M(X)]*2. Все свойства дисперсии Д.С.В. сохраняются и для Н.С.В.
Вопрос 19
Моменты распределения. При решении многих практических задач нет особой необходимости в полной вероятностной характеристике каких-либо случайных величин, которую дает функция плотности распределения вероятностей. Очень часто приходится также иметь дело с анализом случайных величин, плотности вероятностей которых не отображаются аналитическими функциями либо вообще неизвестны. В этих случаях достаточно общее представление о характере и основных особенностях распределения случайных величин можно получить на основании усредненных числовых характеристик распределений.
Числовыми характеристиками случайных величин, которые однозначно определяются функциями распределения их вероятностей, являются моменты.
Начальные моменты
n-го порядка случайной величины X (или просто моменты) представляют собой
усредненные значения n-й степени случайной переменной: mn º
М{Xn}º ![]() =
= ![]() xn p(x) dx, где M{Xn} и
xn p(x) dx, где M{Xn} и ![]() -
символические обозначения математического ожидания и усреднения величины
Хn, которые вычисляются по
пространству состояний случайной величины Х.
-
символические обозначения математического ожидания и усреднения величины
Хn, которые вычисляются по
пространству состояний случайной величины Х.
Соответственно, для случайных
дискретных величин: mn º М{Xn}º ![]() =
=![]() xin pi.
xin pi.
Центральные моменты n-го порядка, это моменты относительно центров распределения (средних значений) случайных величин:
mn º
M{(X-![]() )n}º
)n}º
![]() =
=![]() (x-m1)n p(x) dx
(x-m1)n p(x) dx
mn º M{(X-![]() )n}º
)n}º ![]() =
=![]() (xi-m1)n pi,
где
(xi-m1)n pi,
где ![]() - начальный момент 1-го
порядка (среднее значение величины Х), X0 = X-
- начальный момент 1-го
порядка (среднее значение величины Х), X0 = X-![]() - центрированные значения
величины Х.
- центрированные значения
величины Х.
Связь между центральными и начальными моментами достаточно проста:
m1=0, m2=m2-m12, m3=m3-3m2m1+2m13, m4=m4-4m1m3+6m12m2-3m14, и т.д.
Соответственно, для случайных величин с нулевыми средними значениями начальные моменты равны центральным моментам.
По результатам реализации
случайных величин может производиться только оценка моментов, т.к.
количество измерений всегда конечно и не может с абсолютной точностью отражать
все пространство состояний случайных величин. Результаты измерений - выборка
из всех возможных значений случайной величины (генеральной совокупности).
Оценка моментов, т.е. определение средних значений n-й степени по выборке из N
зарегистрированных значений, производится по формулам: ![]() = (1/N)
= (1/N)![]() xin »
xin »![]() ,
,![]() = (1/N)
= (1/N)![]() (xi-
(xi-![]() )n »
)n »![]()
Вопрос 20
Равномерным называют распределение вероятностей Н.С.В. Х, если на интервале (а,b), которому принадлежат все возможные значения Х, плотность сохраняет постоянное значение, а именно f(x)=1/(b-a); вне этого интервала f(x)=0. Нетрудно убедиться, что интеграл от –бесконечности до бесконечности р(х)dx=1. Для С.В., имеющей равномерное распределение , вероятность того, что С.В. примет значения из заданного интервала (х,х+дельта) прин. [a,b], не зависит от положения этого интервала на числовой оси и пропорциональна длине этого интервала дельта: P{x<X<x+дельта}=интеграл от х до х+дельта 1/b-adt=дельта/b-a. Функция распределения Х имеет вид: F(x)=0, при х<=a, x-a/b-a,при a<x<=b,1при х>b.
Вопрос 21
Случайная величина Х с функцией распределения
F(x)= {0, x<0,
{1- e –μx x³0
называется распределённой по показательному закону с параметром μ. Плотность распределения этой случайной величины получается путём дифференцирования:
f(x)={0, x<0,
{μe–μx x³0.
Интервал времени между двумя последовательными появлениями некоторого редкого события описывается случайной величиной, распределённой по показательному закону.
MX=1/μ DX=1/μ2
Вопрос 22
Потоком событий называют последовательность событий, которые наступают в случайные моменты времени.
Простейшим (пуассоновским) называют поток событий, который обладает следующими тремя свойствами: стационарностью, «отсутствием последействия» и ординарностью.
Свойство стационарности состоит в том, что вероятность появления k событий в любом промежутке времени зависит только от числа k и от длительности t промежутка времени и не зависит от начала его отсчета. Другими словами, вероятность появления k событий за промежуток времени длительностью t есть функция, за-висящая только от k и t.
Свойство «отсутствия последействия» состоит в том, что вероятность появления k событий в любом промежутке времени не зависит от того, появлялись или не появлялись события в моменты времени, предшествующие началу рассматриваемого промежутка. Другими словами, предыстория потока не влияет на вероятности появления событий в ближайшем будущем.
Свойство ординарности состоит в том, что появление двух или более событий за малый промежуток времени практически невозможно. Другими словами, вероятность появления более одного события за малый промежуток времени пренебрежимо мала по сравнению с вероятностью появления только одного события.
Интенсивностью потока l называют среднее число событий, которые появляются в единицу времени.
Если постоянная интенсивность потока l известна, то вероятность появления k событий простейшего потока за время t определяется формулой Пуассона
![]()
Замечание. Поток, обладающий свойством стационарности, называют стационарным; в противном случае—нестационарным.
Вопрос 23
(на отдельном листе)
Вопрос 24
Н.С.В. Х имеет нормальное распределение вероятностей с параметром а и сигма>0, если ее плотность распределения имеет вид: р(х)=1/(корень квадратный из 2пи *сигма) * е в степени –1/2*(x-a/сигма)*2. Если Х имеет нормальное распределение, то будем кратко записывать это в виде Х прибл. N(a,сигма). Так как фи(х)=1/(корень из 2пи)*е в степени –х*2/2 – плотность нормального закона распределения с параметрами а=0 и сигма=1, то функция Ф(х)=1/(корень из 2пи)* интеграл от –бесконечности до х е в степени –t*2/2dt, с помощью которой вычисляется вероятность P{a<=мюn-np/(корень из npq)<=b}, является функцией распределения нормального распределения с параметрами а=0, сигма=1.
Вопрос 25
Функцией (или интегралом вероятностей) Лапласа называется функция
![]()
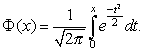 При решении
задач, как правило, требуется найти значение функции по известному значению аргумента
или, наоборот, по известному значению функции требуется найти значение
аргумента. Для этого пользуются таблицей значений функции Лапласа и учитывают
следующие свойства функции
При решении
задач, как правило, требуется найти значение функции по известному значению аргумента
или, наоборот, по известному значению функции требуется найти значение
аргумента. Для этого пользуются таблицей значений функции Лапласа и учитывают
следующие свойства функции ![]()
![]() 10. Функция Лапласа нечётная, т.е.
10. Функция Лапласа нечётная, т.е.
20. Функция Лапласа монотонно возрастающая, причём (
практически можно считать, что уже при ![]() . Так при
. Так при ![]() ).
).

Вопрос 26
Неравенство Чебышева: Если известна дисперсия С.В., то с ее помощью можно оценить вероятность отклонения этой величины на заданное значение от своего мат. ожидания, причем оценка вероятности отклонения зависит лишь от дисперсии. Соответствующую оценку вероятности дает неравенство Чебышева. Неравенство Чебышева является частным случаем более общего неравенства, позволяющего оценить вероятность события, состоящего в том, что С.В. Х превзойдет по модулю произвольное число t>0. PX<=1/t*2 M(X – MX)*2=1/t*2 DX – неравенство Чебышева. Оно справедливо для любых С.В., имеющих дисперсию; оценка вероятности в нем не зависит от закона распределения С.В. Х.
Под законом больших числе понимается обобщенное название группы теорем, утверждающих, что при неограниченном увеличении числа испытаний средние величины стремятся к некоторым постоянным.
Теорема Чебышева: Если последовательность попарно независимых С.В. Х1,Х2,Х3,…,Xn,… имеет конечные мат. ожидания и дисперсии этих величин равномерно ограничены (не превышают постоянного числа С), то среднее арифметическое С.В. сходится по вероятности к среднему арифметическому их мат. ожиданий, т.е. если эпселен – любое положительное число, то: lim при n стремящемся к бесконечности P(|1/n сумма по i от 1 до n Xi – 1/n сумма по i от 1 до n M(Xi)|<эпселен)=1. В частности, среднее арифметическое последовательности попарно независимых величин, дисперсии которых равномерно ограничены и которые имеют одно и тоже мат. ожидание а, сходится по вероятности к мат. ожиданию а, т.е. если эпселен – любое положительное число, то: lim при n стремящемся к бесконечности P(|1/n сумма по i от 1 до n Xi – a|<эпселен)=1.
Теорема Бернулли: Если вероятность успеха в каждом из п независимых испытаний постоянна и равна р, то для произвольного, сколь угодно малого ε > 0 справедливо предельное равенство
![]()
где т — число успехов в серии из п испытаний.
Вопрос 27
Локальная теорема Лапласа. Вероятность того, что в n независимых испытаниях, в каждом из которых вероятность появления события равна р(0<p<1), событие наступит ровно k раз (безразлично, в какой последовательности), приближенно равна (тем точнее, чем больше n). Pn(k)=1/(корень из npq)*фи(х). Здесь Фи(х)=1/(корень из 2пи)*е в степени –х*2/2, x=k – np/(корень из npq). Интегральная теорема Лапласа. Вероятность того, что в n независимых испытаниях, в каждом из которых вероятность появления события равна р(0<p<1), событие наступит не меньше k1 раз и не более k2 раз, приближенно равна: P(k1;k2)=Ф(х’’) – Ф(х’). Здесь Ф(х)=1/(корень из 2пи) * интеграл от0 до х е в степени –(z*2/2)dz – функция Лапласа, х’=(k1 – np)/(корень из npq), х’’=(k2 – np)/(корень из npq).
Вопрос 28
Двумерной называют С.В. (Х,Y), возможные значения которой есть пары чисел (x,y). Составляющие Х и Y, рассматриваемые одновременно, образуют систему двух С.В. Дискретной называют двумерную величину, составляющие которой дискретны. Непрерывной называют двумерную величину, составляющие которой непрерывны. Законом распределения Д.С.В. называют соответствие между возможными значениями и их вероятностями. Функция распределения вероятностей Д.С.В. называют функцию F(X,Y), определяющую для каждой пары чисел (х,y) вероятность того, что Х примет значение, меньшее х, при этом Y примет значение, меньшее y: F(x,y)=P(X<x,Y<y). Свойства:1) Значения функции распределения удовлетворяют двойному неравенству: 0<=F(x,y)<=1. 2) Функция распределения есть неубывающая функция по каждому аргументу:F(x2,y)>=F(x1,y), если х2>x1. F(x,y2)>=F(x,y1), если y2>y1. 3) Имеют место предельные соотношения: 1) F(-бесконечность, у)=0, 2) F(x,-бесконечность)=0, 3) F(-бесконечность, -бесконечность)=0, 4) F(бесконечность, бесконечность)=1. 4) а) при у=бесконечность функция распределения системы становится функцией распределения составляющей Х: F(x,бесконечность)=F1(x). Б) при х=бесконечность функция распределения системы становится функцией распределения составляющей У: F(бесконечность, у)=F2(y).
Вопрос 29
Вопрос 30
Корреляционным моментом СВ x и h называется мат. ожидание произведения отклонений этих СВ. mxh=М((x—М(x))*(h—М(h)))
Для вычисления корреляционного момента может быть использована формула:
mxh=М(x*h)—М(x)*М(h) Доказательство: По определению mxh=М((x—М(x))*(h—М(h))) По свойству мат. ожидания
mxh=М(xh—М(h)—hМ(x)+М(x)*М(h))=М(xh)—М(h)*М(x)—М(x)*М(h)+М(x)*М(h)=М(xh)—М(x)*(h)
Предполагая, что x и h независимые СВ, тогда mxh=М(xh)—М(x)*М(h)=М(x)*М(h)—М(x)*М(h)=0; mxh=0. Можно доказать, что если корреляционный момент=0, то СВ могут быть как зависимыми, так и независимыми. Если mxh не равен 0, то СВ x и h зависимы. Если СВ x и h зависимы, то корреляционный момент может быть равным 0 и не равным 0. Можно показать, что корреляционный момент характеризует степень линейной зависимости между составляющими x и h. При этом корреляционный момент зависит от размерности самих СВ. Чтобы сделать характеристику линейной связи x и h независимой от размерностей СВ x и h, вводится коэффициент корреляции:
Кxh=mxh/s(x)*s(h) Коэффициент корреляции не зависит от разностей СВ x и h и только показывает степень линейной зависимости между x и h, обусловленную только вероятностными свойствами x и h. Коэффициент корреляции определяет наклон прямой на графике в системе координат (x,h) Свойства коэффициента корреляции.
1. -1<=Кxh<=1
Если Кxh =±1, то линейная зависимость между x и h и они не СВ.
2. Кxh>0, то с ростом одной составляющей, вторая также в среднем растет.
Кxh<0, то с убыванием одной составляющей, вторая в среднем убывает.
3. D(x±h)=D(x)+D(h)±2mxh
Доказательство.
D(x±h)=M((x±h)2)—M2(x±h)=M(x2±2xh+h2)—(M(x)±M(h))2=M(x2)±2M(xh)+M(h2)—+M2(x)+2M(x)*M(h)—M2(h)=D(x)+D(h)±2(M(xh))—M(x)*M(h)=D(x)+D(h)±2mxh
Вопрос 31
Мат. статистика опирается на теорию вероятностей, и ее цель – оценить характеристики генеральной совокупности по выборочным данным. Генеральной совокупностью называется вероятностное пространство {омега,S,P} (т.е. пространство элементарных событий омега с заданным на нем полем событий S и вероятностями Р) и определенная на этом пространстве С.В. Х. Случайной выборкой или просто выборкой объема n называется последовательность Х1,Х2,…,Xn, n независимых одинаково распределенных С.В., распределение каждой из которых совпадает с распределением исследуемой С.В. Х. Иными словами, случайная выборка – это результат n последовательных и независимых наблюдений над С.В. Х, представляющей генеральную совокупность.
Вопрос 32
Расположив элементы выборки в порядке неубывания, получим вариационный ряд х1 х2, ...-, хп. Если в вариационном ряду есть повторяющиеся элементы, то выборку можно записать в виде статистического ряда распределения, т.е. в виде таблицы
![]()
в которой хi'; (i= 1, 2,..., к) — это варианты
(расположенные по возрастанию различные
элементы выборки), а![]()
отвечающие этим значениям частости (здесь mi — частота варианты х'i, т.е. количество ее появлений в выборке). При этом, очевидно,
![]() Кривая распределения частости - это ломаная с вершинами (х’i; Pi).
Кривая распределения частости - это ломаная с вершинами (х’i; Pi).
Выборочное среднее (4.1.1) и выборочную дисперсию (4.1.8) при этом можно вычислить по формулам
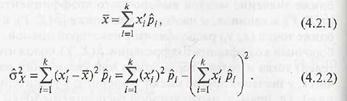
Для непрерывных случайных величин при достаточно больших объемах выборки п вместо статистического ряда распределения используют интервальный вариационный ряд
![]()
где v - число интервалов одинаковой ширины h = (xn-x1)/(1+3,322lgn) (х1 и хп - соответственно минимальный и максимальный элементы выборки; значение h рассчитывается с числом знаков после запятой, на единицу большим, чем в исходныхданных). Границы интервалов [aj, aj+i) рассчитываются по правилу: a1=x1-h/2, а2 = а1 + h, а3 = а2 + h, ...;
формирование интервалов заканчивается, как только для конца av+1 очередного интервала выполняется условие av+1 > хп. Выборочная ча-
стость ![]() где mi — число вариант, попавших в i-й интервал
где mi — число вариант, попавших в i-й интервал
(i= 1,2, ...,v). Выборочным аналогом плотности распределения fx(x) случайной величины X служит выборочная плотность распределения
Вопрос 33
Выборочным аналогом плотности распределения fx(x) случайной величины X служит выборочная плотность распределения
![]() при х Î[ai; ai+1) (i=
1, 2,..., V), ее график
называется гис
при х Î[ai; ai+1) (i=
1, 2,..., V), ее график
называется гис
тограммой, а ломаная с вершинами в точках![]() где через
где через
х’=(ai+ai+1)/2 обозначены середины интервалов, — полигоном частот.
Выборочное среднее и выборочную дисперсию при этом вычисляют по формулам (4.2.1), (4.2.2)
соответственно, в которых к = v.
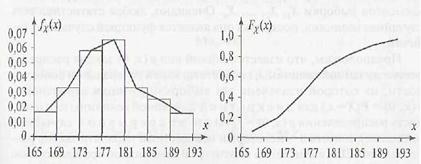
По выборочной плотности распределения легко построить выборочную функцию распределения, при
этом линия, соединяющая точки![]() называется кумулятой
называется кумулятой
Гистограмма (тонкая линия), полигон частот (полужирная линия) (а) и кумулята (б)
Вопрос 34
Вопрос 35
Прежде всего, от оценки θn хотелось бы требовать, чтобы по мере роста числа наблюдений п она стремилась к оцениваемому параметру, т.е. чтобы для любого сколь угодно малого £>0 было справедливо предельное равенство
![]()
Также от «хорошей» оценки естественно требовать, чтобы она не содержала систематической ошибки, т.е. при любом фиксированном объеме выборки результат осреднения по всем возможным выборкам данного объема должен приводить к точному значению параметра:
![]()
Наконец, от оценки θn желательно требовать, чтобы она была наиболее точной в некотором классе оценок в, т.е. имела минимальную дисперсию:
![]()
Вопрос 36
Статистической оценкой K * неизвестного параметра K теоретического распределения называют функцию f(X1,X2,…,Xn) от наблюдаемых С.В. X1,X2,…,Xn. Точечной называют статистическую оценку, которая определяется одним числом K *=f(x1,x2,…,xn), где х1,х2,…,xn – результаты n наблюдений над количественным признаком Х (выборка). Несмещенной называют точечную оценку, мат. ожидание которой равно оцениваемому параметру при любом объеме выборки. Смещенной называют точечную оценку, мат. ожидание которой не равно оцениваемому параметру. Несмещенной оценкой генеральной средней (мат. ожидания) служит выборочная средняя: Хв=(сумма по i от 1 до k nixi)/n, где xi – варианта выборки, ni – частота варианты xi, n=сумма по i от 1 до k ni – объем выборки.
Вопрос 37
Вопрос38
Метод моментов точечной оценки неизвестных параметров заданного распределения состоит в приравнивании теоретических моментов соответствующим эмпирическим моментам того же порядка. Если распределение определяется одним параметром, то для его отыскания приравнивают один теоретический момент одному эмпирическому моменту того же порядка. Например, можно приравнять начальный теоретический момент первого порядка начальному эмпирическому моменту первого порядка: v1=M1. Учитывая, что v1=M(X) и М1=Хв, получим М(Х)=Хв. Если распределение определяется двумя параметрами, то приравнивают два теоретических момента двум соответствующим эмпирическим моментам того же порядка. Учитывая, что v1=M(X),M1=Хв,мю=D(X),m2=Dв, имеем систему: М(Х)=Хв, D(X)=Dв.
Метод наибольшего правдоподобия точечной оценки неизвестных параметров заданного распределения сводится к отысканию максимума функции одного или нескольких оцениваемых параметров. Д.С.В. Пусть Х – Д.С.В., которая в результате n опытов приняла возможные значения х1,х2,…,xn. Допустим, что вид закона распределения величины Х задан, но неизвестен параметр K, которым определяется этот закон; требуется найти его точечную оценку K*=K (x1,x2,…,xn). Обозначим вероятность того, что в результате испытания величина Х примет значение xi через р(xi;K). Функцией правдоподобия Д.С.В. Х называют функцию аргумента K: L (x1,x2,…,xn;K)=p(x1;K)*p(x2;K)…p(xn;K). Оценкой наибольшего правдоподобия параметра K называют такое его значение K*, при котором функция правдоподобия достигает максимума. Функции L и lnL достигают максимума при одном и том же значении K, поэтому вместо отыскания максимума функции L ищут, что удобнее, максимум функции lnL. Н.С.В. Пусть Х – Н.С.В., которая в результате n испытаний приняла значения х1,х2,…,xn. Допустим, что вид плотности распределения – функции f(x) – задан, но неизвестен параметр K, которым определяется эта функция. Функцией правдоподобия Н.С.В. Х называют функцию аргумента K: L(x1,x2,…,xn;K)=f(x1;K)*f(x2;K)…f(xn;K).
Вопрос 39
Интервальной называют оценку, которая определяется двумя числами – концами интервала, покрывающего оцениваемый параметр. Доверительный интервал – это интервал, который с заданной надежностью гамма покрывает заданный параметр
Интервальной оценкой (с надежностью гамма) среднего квадратического отклонения сигма нормально распределенного количественного признака Х по «исправленному» выборочному среднему квадратическому отклонению s служит доверительный интервал s(1-q)<сигма<s(1+q), при q<1; 0<сигма<s(1+q), при q>1. 3. Интервальной оценкой ( с надежностью гамма) неизвестной вероятности р биномиального распределения по относительной частоте w служит доверительный интервал ( с приближенными концами р1 и р2).
Вопрос 40
Интервальной называют оценку, которая определяется двумя числами – концами интервала, покрывающего оцениваемый параметр. Доверительный интервал – это интервал, который с заданной надежностью гамма покрывает заданный параметр. 1. Интервальной оценкой с надежностью гамма мат. ожидания а нормально распределенного количественного признака Х по выборочной средней Хв при известном среднем квадратическом отклонении сигма генеральной совокупности служит доверительный интервал: Хв – t(сигма/корень из n)<a<Хв+t(сигма/корень из n), где t(сигма/корень из n)=дельта – точность оценки, n – объем выборки, t – значение аргумента функции Лапласа Ф(t), при котором Ф(t)=гамма/2; при неизвестном сигма (и объеме выборки n<30) Хв – t гамма (s/корень из n)<a<Хв+t гамма (s/корень из n), где s-исправленное выборочное среднее квадратическое отклонение
Вопрос 41
Вопрос 42
В статистике рассматриваются гипотезы двух типов:
1. Параметрические – гипотезы о значении параметра известного распределения;
2. Непараметрические – гипотезы о виде распределения.
Обычно выделяют основную гипотезу – нулевую (H0). Пример: математическое ожидание признака x, который распределен по нормальному закону и дисперсия его известна, а H0: M(x) = a. Предполагаем, что известна дисперсия Конкурирующая гипотеза имеет вид: H1: M(x) ¹ a;
H1: M(x) > a, либо H1: M(x) = a1. Для проверки гипотез используются критерии, и они представляют собой специальным образом подобранные СВ, k – точечный или приближенный закон, который известен.
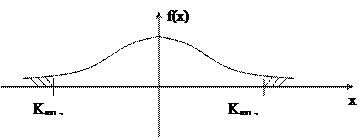
Обычно предполагается, что если гипотеза Н0 выполняется, то вычисляемая по выборочным данным kнабл. Этого критерия и гипотеза Н0 принимается, если kнабл.Î (kкритич. левостор.; kкритич. правостор.) Если kнабл. попадает в критическую область (все остальные значения k Î(- ¥ ; kкритич. лев.) È (kкритич. прав. ; ¥), то гипотеза Н0 отвергается и принимается конкурирующая гипотеза Н1. При этом возможны ошибки двух типов: Первого рода: что гипотеза Н0 отвергается, в то время, как она верна. Вероятность этой ошибки: P(H1/H0) = a - уровень значимости критерия. Критерий подбирается так, чтобы a была как можно меньше. Второго рода: что отвергается гипотеза Н1, в то время, как она верна. b = P(H0/H1) Мощностью критерия – (1-b) - вероятность попасть точке-выборке в критическое множество, когда верна конкурирующая гипотеза.
1-b = P(H1/H1)
Вопрос 43
Вопрос 44
По независимым выборкам, объемы которых n1, n2, извлеченным из нормальных генеральных совокупностей, найдены исправленные выборочные дисперсии s^2*x и s^2*y. Требуется сравнить эти дисперсии.
Правило I. Для того чтобы при заданном уровне значимости α, проверить нулевую гипотезу HQ: D(X) = D(Y) о равенстве генеральных дисперсий нормальных совокупностей при конкурирующей гипотезе Ho: D (X) > D (Y), надо вычислить наблюдаемое значение критерия (отношение большей исправленной дисперсии к меньшей)
![]()
и по таблице критических точек распределения Фишера—Снедекора, по заданному уровню значимости а и числам степеней свободы k1=n1—1, k2 = n2—1 (k1—число степеней свободы большей исправленной дисперсии) найти критическую точку FKР(a; k1, k2). Если Fнабл < Fкр— нет оснований отвергнуть нулевую гипотезу. Если Fна,л > Fкр — нулевую гипотезу отвергают.
Правило 2. При конкурирующей гипотезе Н1: D(X)¹D(Y) критическую точку FKP (α/2; k1 ,k2) ищут по уровню значимости а/2 (вдвое меньшему заданного) и числам степеней свободы k1 и k2 (k1—число степеней свободы, большей дисперсии). Если FHАБЛ < Fкр — нет оснований отвергнуть нулевую гипотезу. Если Fнабл > Fкр — нулевую гипотезу отвергают.
Вопрос 45
Вопрос 46
Разобьем множество возможных значений случайной величины X Hav разрядов (для непрерывной случайной величины роль разрядов играют интервалы значений, а для дискретной — отдел ь-ные возможные значения или их группы). Выдвинем нулевую гипотезу Но: Fx(x) = Fтеор(x) (состоящую в том, что генеральная совокупность распределена по закону Fтеор(x)) при альтернативной гипотезе Н1: Fx(x) ¹ FTeop(x). Одним из критериев согласия выборочного и теоретического распределений (т.е. критериев соответствия генеральной совокупности определенному закону распределения) является критерий X^2 (критерий Пирсона), который основывается на том, что распределение статистики
![]()
(где л, — число попаданий элементов выборки в i-й разряд, п - общее число элементов выборки, apiтеop — теоретическая вероятность попадания случайной величины Х в i-и разряд при условии истинности нулевой гипотезы) не зависит от выдвинутой гипотезы и определяется только числом степеней свободы k = v — l — 1, где v — число разрядов, аl— число оцениваемых параметров. Формулы закона распределения случайной величины X^2 довольно сложны, и мы их приводить не будем, но для этого распределения составлены таблицы значений X^2k;y таких, что Р{X2 < X^2k;y } = γ (табл. П. 3).
Если выбрать уровень значимости а, то надежность γ = 1 — а = — Р{X2 < X^2k;y } и критическая область определяется неравенством X2 набл< X^2k;y
Обратим внимание на то, что критерий Пирсона можно использовать только в том случае, когда nртеор³5, поэтому разряды, для кото-, рых это условие не выполняется, необходимо объединить с соседними.
Вопрос 47
С помощью методов регрессионного анализа строятся и проверяются модели, характеризующие связь между одной эндогенной (зависимой) переменной и одной или более экзогенными (независимыми) переменными. Независимые переменные называются регрессором.
Направленность связи между переменными определяется путем предварительного обоснования и включается в модель в качестве исходной гипотезы. Задача регрессионного анализа – проверка статистической состоятельности модели, если данная гипотеза верна. Регрессионный анализ не в состоянии «доказать» гипотезу, он может лишь подтвердить ее статистически или отвергнуть.
Метод наименьших квадратов (МНК, англ. Ordinary Least Squares, OLS) является одним из основных методов определения параметров регрессионных уравнений, дающий наилучшие линейные несмещенные оценки (теорема Гаусса–Маркова).
Метод наименьших квадратов заключается в том, чтобы определить вид кривой, характер которой в наибольшей степени соответствует эмпирическим данным. Такая кривая должна обеспечить наименьшее значение суммы квадратов отклонений эмпирических значений величин показателя от значений, вычисленных согласно уравнению этой кривой:
Уравнение линейной регрессии. Обычно признак Y рассматривается как функция многих аргументов — x1, x2, x3, ...— и может быть записана в виде:
y = a + bx1 + cx2 + dx3 + ... ,
где: а, b, с и d —
параметры уравнения, определяющие соотношение между аргументами и функцией. В
практике учитываются не все, а лишь некоторые аргументы, в простейшем случае,
как при описании линейной регрессии, — всего один: y = a + bx
В этом уравнении параметр а — свободный член; графически он представляет
отрезок ординаты (у) в системе прямоугольных координат. Параметр b
называется коэффициентом регрессии. С точки зрения аналитической геометрии b—
угловой коэффициент, определяющий наклон линии регрессии по отношению к осям,
координат. В области регрессионного анализа этот параметр показывает, насколько
в среднем величина одного признака (Y) изменяется при изменении на
единицу меры другого корреляционно связанного с Y признака X.
Коэффициенты уравнения парной
линейной регрессии. В случае линейной
зависимости уравнение регрессии является уравнением прямой линии. Таких
уравнений два: Y = a1 + by/xX — прямое и X = a2
+ bx/yY — обратное, где: a и b – коэффициенты, или
параметры, которые надлежит определить.
Значение коэффициентов регрессии вычисляется по формуле:
![]()
![]()
Коэффициенты регрессии b
имеют размерность, равную отношению размерностей изучаемых показателей X
и Y, и тот же знак, что и коэффициент корреляции.
Коэффициенты а определяются по формуле:
![]()
![]()
Определение параметров парной линейной регрессии
Определение параметров линейной регрессии – одна из задач регрессионного
анализа. Она решается способом наименьших квадратов, основанным на требовании,
чтобы сумма квадратов отклонений вариант от линии регрессии была наименьшей.
Этому требованию удовлетворяет следующая система нормальных уравнений:
![]()
![]()
Формулы для определения параметров а и b принимают следующие выражения:
![]()
![]()
Уравнение линейной регрессии можно выразить в виде отклонений вариант от их средних арифметических:
![]()
![]()
В таком случае система нормальных уравнений для определения параметров а и b будет следующая:
![]()
![]()
Система уравнений парной линейной регрессии:
![]()
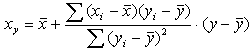
Эти уравнения удобны для определения параметров при отыскивании эмпирических уравнений регрессии в практической работе для точности прогнозирования результатов.
Вопрос 49
Временным рядом будем называть таблицу, в верхней строке которой находится счетное множество моментов времени (с постоянной дискретностью, напр. t=2, 5, 8, 11,...), в нижней - значение некоторого показателя Y. Предположим, без ограничения общности, что Y является функцией времени. Все другие факторы, кроме времени, оказывающие влияние на Y, аккумулируем и считаем. что они представляют собой случайный процесс Z(t), математическое ожидание которого равно нулю. Таким образом Yt=f(t)+Z(t). Функция f(t) - детерминированная составляющая, она называется трендом.
