
Рефераты по биологии
Рефераты по экономике
Рефераты по москвоведению
Рефераты по экологии
Краткое содержание произведений
Рефераты по физкультуре и спорту
Топики по английскому языку
Рефераты по математике
Рефераты по музыке
Остальные рефераты
Рефераты по авиации и космонавтике
Рефераты по административному праву
Рефераты по безопасности жизнедеятельности
Рефераты по арбитражному процессу
Рефераты по архитектуре
Рефераты по астрономии
Рефераты по банковскому делу
Рефераты по биржевому делу
Рефераты по ботанике и сельскому хозяйству
Рефераты по бухгалтерскому учету и аудиту
Рефераты по валютным отношениям
Рефераты по ветеринарии
Рефераты для военной кафедры
Рефераты по географии
Рефераты по геодезии
Рефераты по геологии
Реферат: Обработка результатов экспериментов и наблюдений
Реферат: Обработка результатов экспериментов и наблюдений
Prusakov Danil.
Обработка результатов эксперимента
Изложены некоторые разделы математической обработки результатов наблюдений и экспериментов о действиях со случайными величинами, определения и оценки законов их распределения, аналитического и графического отображения результатов.
ВВЕДЕНИЕ
При исследовании технических систем могут использоваться теоретические и эмпирические методы познания. Каждое из этих направлений обладает относительной самостоятельностью, имеет свои достоинства и недостатки. В общем случае, теоретические методы в виде математических моделей позволяют описывать и объяснять взаимосвязи элементов изучаемой системы или объекта в относительно широких диапазонах изменения переменных величин. Однако при построении теоретических моделей неизбежно введение каких-либо ограничений, допущений, гипотез и т.п. Поэтому возникает задача оценки достоверности ( адекватности ) полученной модели реальному процессу или объекту. Для этого проводится экспериментальная проверка разработанных теоретических моделей. Практика является решающей основой научного познания. В ряде случаев именно результаты экспериментальных исследований дают толчок к теоретическому обобщению изучаемого явления. Экспериментальное исследование дает более точное соответствие между изучаемыми параметрами. Но не следует и преувеличивать результаты экспериментальных исследований, которые справедливы только в пределах условий проведенного эксперимента.
Таким образом, теоретические и экспериментальные исследования дополняют друг друга и являются составными элементами процесса познания окружающего нас мира.
Как правило, результаты экспериментальных исследований нуждаются в определенной математической обработке. В настоящее время процедура обработки экспериментальных данных достаточно хорошо формализована и исследователю необходимо только ее правильно использовать. Круг вопросов, решаемых при обработке результатов эксперимента, не так уж велик. Это - вопросы подбора эмпирических формул и оценка их параметров, вопросы оценки истинных значений измеряемых величин и точности измерений, вопросы исследования корреляционных зависимостей и некоторые другие.
Настоящее учебное пособие не претендует на оригинальность. Оно содержит некоторые результаты фундаментальных и прикладных работ в области обработки результатов экспериментальных исследований [1...13]. Пособие может служить практическим руководством по обработке результатов эксперимента как студентам, так и научным сотрудникам и инженерам.
1. ОШИБКИ ИЗМЕРЕНИЙ
Основой всего естествознания является наблюдение и эксперимент.
Наблюдение - это систематическое, целенаправленное восприятие того или иного объекта или явления без воздействия на изучаемый объект или явление. Наблюдение позволяет получить первоначальную информацию по изучаемому объекту или явлению.
Эксперимент - метод изучения объекта, когда исследователь активно и целенаправленно воздействует на него путем создания искусственных условий или использует естественные условия, необходимые для выявления соответствующих свойств. Достоинствами эксперимента по сравнению с наблюдением реального явления или объекта является:
1. Возможность изучения в «чистом виде», без влияния побочных факторов, затемняющих основной процесс;
2. В экспериментальных условиях можно получить результат более быстро и точно;
3. При эксперименте можно проводить испытания столько раз, сколько это необходимо.
Результат эксперимента или измерения всегда содержит некоторую погрешность. Если погрешность мала, то ею можно пренебречь. Однако при этом неизбежно возникают два вопроса: во-первых, что понимать под малой погрешностью, и, во-вторых, как оценить величину погрешности. То есть, и результаты эксперимента нуждаются в определенном теоретическом осмыслении.
1.1. Цели математической обработки результатов эксперимента
Целью любого эксперимента является определение качественной и количественной связи между исследуемыми параметрами, либо оценка численного значения какого-либо параметра.
В некоторых случаях вид зависимости между переменными величинами известен по результатам теоретических исследований. Как правило, формулы, выражающие эти зависимости, содержат некоторые постоянные, значения которых и необходимо определить из опыта.
Другим типом задачи является определение неизвестной функциональной связи между переменными величинами на основе данных эксперимента. Такие зависимости называют эмпирическими.
Однозначно определить неизвестную функциональную зависимость между переменными невозможно даже в том случае, если бы результаты эксперимента не имели ошибок. Тем более не следует этого ожидать, имея результаты эксперимента, содержащие различные ошибки измерения.
Поэтому следует четко понимать, что целью математической обработки результатов эксперимента является не нахождение истинного характера зависимости между переменными или абсолютной величины какой-либо константы, а представление результатов наблюдений в виде наиболее простой формулы с оценкой возможной погрешности ее использования.
1.2. Виды измерений и причины ошибок
Под измерением понимают сравнение измеряемой величины с другой величиной, принятой за единицу измерения.
Различают два типа измерений: прямые и косвенные. При прямом измерении измеряемая величина сравнивается непосредственно со своей единицей меры. Например, измерение микрометром линейного размера, промежутка времени при помощи часовых механизмов, температуры - термометром, силы тока - амперметром и т.п. Значение измеряемой величины отсчитывается при этом по соответствующей шкале прибора.
При косвенном измерении измеряемая величина определяется (вычисляется) по результатам измерений других величин, которые связаны с измеряемой величиной определенной функциональной зависимостью. Например, измерение скорости по пройденному пути и затраченному времени, измерение плотности тела по измерению массы и объема, температуры при резании по электродвижущей силе, величины силы - по упругим деформациям и т.п.
При
измерении любой физической величины производят проверку и установку соответствующего
прибора, наблюдение их показаний и отсчет. При этом никогда истинного значения
измеряемой величины не получить. Это объясняется тем, что измерительные
средства основаны на определенном методе измерения, точность которого конечна.
При изготовлении прибора задается класс точности. Его погрешность определяется
точностью делений шкалы прибора. Если шкала линейки нанесена через 1 мм , то
точность отсчета ![]() 0,5 мм не изменить
если применим лупу для рассматривания шкалы. Аналогично происходит измерение и
при использовании других измерительных средств.
0,5 мм не изменить
если применим лупу для рассматривания шкалы. Аналогично происходит измерение и
при использовании других измерительных средств.
Кроме приборной погрешности на результат измерения влияет еще ряд объективных и субъективных причин, обуславливающих появление ошибки измерения - разности между результатом измерения и истинным значением измеряемой величины. Ошибка измерения обычно неизвестна, как неизвестно и истинное значение измеряемой величины. Исключение составляют измерения известных величин при определении точности измерительных приборов или их тарировке. Поэтому одной из важнейших задач математической обработки результатов эксперимента и является оценка истинного значения измеряемой величины по данным эксперимента с возможно меньшей ошибкой.
1.3. Типы ошибок измерения
Кроме приборной погрешности измерения (определяемой методом измерения) существуют и другие, которые можно разделить на три типа:
1. Систематические погрешности обуславливаются постоянно действующими факторами. Например, смещение начальной точки отсчета, влияние нагревания тел на их удлинение, износ режущего лезвия и т.п. Систематические ошибки выявляют при соответствующей тарировке приборов и потому они могут быть учтены при обработке результатов измерений.
2. Случайные ошибки содержат в своей основе много различных причин, каждая из которых не проявляет себя отчетливо. Случайную ошибку можно рассматривать как суммарный эффект действия многих факторов. Поэтому случайные ошибки при многократных измерениях получаются различными как по величине, так и по знаку. Их невозможно учесть как систематические, но можно учесть их влияние на оценку истинного значения измеряемой величины. Анализ случайных ошибок является важнейшим разделом математической обработки экспериментальных данных.
3. Грубые ошибки (промахи) появляются вследствие неправильного отсчета по шкале, неправильной записи, неверной установки условий эксперимента и т.п. Они легко выявляются при повторном проведении опытов.
В дальнейшем будем считать, что систематические и грубые ошибки из результатов эксперимента исключены.
1.4. Свойства случайных ошибок
Случайные ошибки бывают как положительные, так и отрицательные разной величины, не превосходящей определенного предела. Если обозначить через Х истинное значение измеряемой величины, а результат первого измерения - à1, то разность
Х - à1 = х1 или à1 - Х = х1
называют истинной абсолютной ошибкой одного измерения. Одновременно она является случайной (при исключении систематических и грубых ошибок).
Если измерения провести многократно в одних и тех же условиях, то результаты отдельных измерений одинаково надежны. Такую совокупность измерений а1, а2 ...аn называют равноточными измерениями. Если проанализировать достаточно большую серию равноточных измерений и соответствующих случайных ошибок измерений, то можно выделить 4 свойства случайных ошибок:
1. Число положительных ошибок почти равно числу отрицательных;
2. Мелкие ошибки встречаются чаще, чем крупные;
3. Величина наиболее крупных ошибок не превосходит некоторого определенного предела, зависящего от точности измерения. Самую большую ошибку в ряду равноточных измерений называют предельной ошибкой;
4. Частные от деления алгебраической суммы всех случайных ошибок на их общее близко к нулю, т.е.
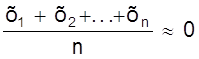 .
.
На основе указанных свойств при учете некоторых допущений математически достаточно строго выводится закон распределения ошибок, описываемый следующей функцией:
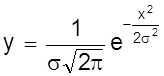 ,
,
где s - дисперсия измерений (см. ниже);
е - основание натуральных логарифмов;
х - истинная абсолютная ошибка измерений.
Иначе эту зависимость называют формулой случайных ошибок, формулой Гаусса. На рис.1 приведены кривые Гаусса с различной величиной s.
Рис. 1. Кривая случайных ошибок
Закон распределения случайных ошибок является основным в математической теории погрешностей. Иначе его называют нормальным законом распределения. Особое значение в пользу широкого использования закона Гаусса имеет следующее обстоятельство: если суммарная ошибка измерения появляется в результате совместного действия ряда причин, каждая их которых вносит малую долю в общую ошибку (т.е. нет доминирующих причин), то по какому бы закону не были распределены ошибки, вызываемые каждой из причин, результат их совместного действия приведет
к нормальному распределению ошибок. Эта закономерность является следствием так называемой центральной предельной теоремы Ляпунова и хорошо соотносится с введенным понятием случайной ошибки.
Наряду с нормальным законом распределения ошибок могут встречаться и другие.
1.5. Наиболее вероятное значение измеряемой величины
Допустим, что для определения истинного значения Х измеряемой величины было сделано n равноточных измерений с результатами а1, а2 .. .аn. Естественно, что ряд этих чисел будет больше Х, другие меньше Х и неясно, какое из этих чисел ближе всего подходит к Х.
Представим результаты измерений в виде очевидных равенств:
а1 = Х - Dх1; а2 = Х - Dх2; ... ; аn = Х - Dхn.
Естественно, что истинные абсолютные ошибки Dхi могут принимать как положительные, так и отрицательные значения.
Суммируя левые и правые стороны равенств получим
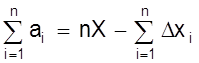 .
.
Поделим обе части равенства на число измерений n и получим
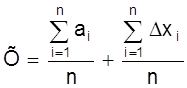 .
.
Величина
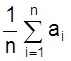 является
среднеарифметическим величины Х. Если число n достаточно
велико ( при n®¥), то
согласно четвертому свойству случайных ошибок
является
среднеарифметическим величины Х. Если число n достаточно
велико ( при n®¥), то
согласно четвертому свойству случайных ошибок
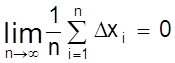 .
.
Это же видно и по кривой Гаусса (рис. 1), где всякой положительной погрешности соответствует равная ей отрицательная.
Из изложенного следует, что
Х = а при n ® ¥,
т.е. при бесконечном числе измерений истинное значение измеряемой величины равно среднеарифметическому значению результатов всех измерений. При ограниченном числе измерений истинное значение будет отличаться от среднеарифметического и необходимо оценить величину этого расхождения: Х = а ± Dх.
Следует еще раз подчеркнуть, что среднеарифметическое значение, принимаемое за истинное значение измеряемой величины, является наиболее вероятным значением. Среди значений аi могут оказаться значения, которые в действительности ближе к истинному значению.
Отклонение Dх вероятнейшего значения а от его истинного значения Х называют истинной абсолютной ошибкой.
1.6. Оценка точности измерений
Для ряда равноточных измерений а1, а2 ...аn определим его среднеарифметическое значение а и составим разности (а - а1), (а - а2), ..., (а - аn).
Каждую из этих разностей
называют вероятнейшей ошибкой отдельного измерения (Vi).
Вероятнейшие ошибки, как и истинные ошибки Dхi
= (Х - аi), бывают положительные и отрицательные, нулевые.
Рассмотрим 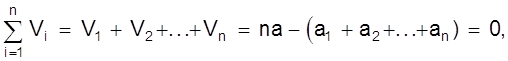 т.е. алгебраическая
сумма вероятнейших ошибок равна нулю при любом числе измерений. Истинные
случайные ошибки таким свойством не обладают.
т.е. алгебраическая
сумма вероятнейших ошибок равна нулю при любом числе измерений. Истинные
случайные ошибки таким свойством не обладают.
Вероятнейшие ошибки Vi лежат в основе математической обработки результатов измерений: именно по ним вычисляют предельную абсолютную ошибку Dаi среднеарифметического а и тем самым оценивают точность результата измерений.
Средняя истинная случайная ошибка (иначе - среднее отклонение отдельного измерения) определяется выражением (Dх1+Dх2+...+Dхn)/n.
Величина [(Dх1)2+(Dх2)2+...+(Dхn)2]/n представляет средний квадрат случайной ошибки или
дисперсию S2 выборки (при ограниченном n) или
генеральной совокупности s2
(при бесконечном n). Средняя квадратичная ошибка отдельного измерения S = 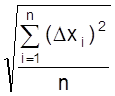 является
лучшим критерием точности, чем средняя случайная ошибка, т.к. не происходит
компенсации положительных и отрицательных ошибок Dхi и сильнее учитывается действие крупных ошибок.
является
лучшим критерием точности, чем средняя случайная ошибка, т.к. не происходит
компенсации положительных и отрицательных ошибок Dхi и сильнее учитывается действие крупных ошибок.
Поскольку
истинное значение Х измеряемой величины неизвестно, то неизвестны и истинные
случайные ошибки ![]() хi.
Для определения средней квадратичной
ошибки S используется
положение теории случайных ошибок, что при большом числе измерений n справедливо равенство
хi.
Для определения средней квадратичной
ошибки S используется
положение теории случайных ошибок, что при большом числе измерений n справедливо равенство
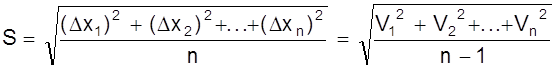 .
.
Различный
знаменатель объясняется тем, что величины ![]() хi
являются независимыми, а из n величин Vi независимыми
являются n-1, т.к. в величину Vi входит а, само определяемое из этих же n
измерений.
хi
являются независимыми, а из n величин Vi независимыми
являются n-1, т.к. в величину Vi входит а, само определяемое из этих же n
измерений.
Важно, что не зная самих истинных случайных ошибок удается вычислить среднюю квадратичную ошибку определенного измерения:
S = ±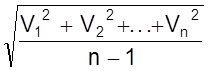 .
.
Оценим теперь погрешность результата всей серии эксперимента, т.е. определим величину Dх = Х - а.
Для этого проведем преобразование выражения
Sn2 = 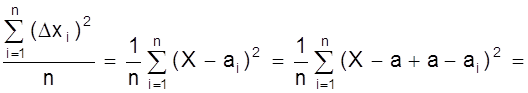
= 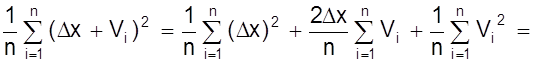
= 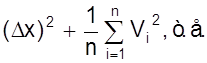
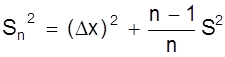 .
.
![]() Если
повторить серии по n измерений в каждой N ðàç,
ìîæíî ïîëó÷ить средние значения а1, а2,
... , аN и погрешности результатов измерений
Если
повторить серии по n измерений в каждой N ðàç,
ìîæíî ïîëó÷ить средние значения а1, а2,
... , аN и погрешности результатов измерений
(Dх)1 = (Х - а1); (Dх)2 = (Х - а2); ... ; (Dх)N = (Х - аN)
и среднюю среднеквадратичную погрешность серии
![]() Sa2 =
Sa2 = 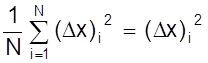 .
.![]()
При большом числе N S2a ® s2a
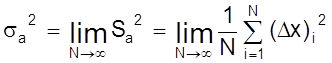 .
.
Усредняя выражение S2n по числу серий N, получаем
![]()
![]() Sa2 = (Dx)2 = Sn2 -
Sa2 = (Dx)2 = Sn2 - 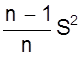 .
.
Учитывая что при большом n S2n ® s2 и S2 ® s2 получаем искомую
связь между дисперсиями всего опыта s2a и отдельного эксперимента [i1] s2
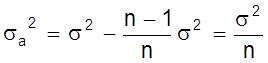 ,
,
т.е. дисперсия s2a результата серии из n измерений в n раз меньше дисперсии отдельного измерения. При ограниченном числе n измерений приближенным выражением s2a будет S2a
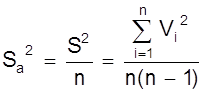 .
.
Выражения s2a и S2a отражают фундаментальный закон возрастания точности при росте числа наблюдений. Из него следует, что желая повысить точность измерений в 2 раза мы должны сделать вместо одного - четыре измерения; чтобы повысить точность в 3 раза, нужно увеличить число измерений в 9 раз и т.д.
1.7. Понятие доверительного интервала и доверительной вероятности
Как установлено ранее, истинное значение измеряемой величины Х отличается от среднеарифметического a на некоторую величину Dx. На рис. 2 представлено расположение истинного значения Х и а, полученного из некоторых измерений а1, а2, а3.
Ясно, что случайные величины а1, а2, а3 обусловят случайный характер абсолютной погрешности Dx результата серии измерений, которая будет распределена по закону Гаусса:
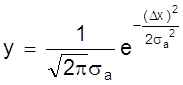 .
.
Рис. 2. Взаимное расположение Х и а, полученных
из трех измерений а1, а2, а3
Тогда вместо выражения Х = а ± Dх можно записать а - Dх £ Х £ а + D.
Интервал (а - Dх; а + Dх), в который по определению попадает истинное значение X называют доверительным интервалом. Надежностью (уровнем значимости) результата серии измерений называется вероятность a того, что истинное значение X измеряемой величины попадет в доверительный интервал. Вероятность a выражается в долях единицы или процентах. Графически надежность отражается площадью под кривой нормального распределения в пределах доверительного интервала, отнесенной к общей площади. Выбор надежности определяется характером производимых измерений. Например, к деталям самолета предъявляются более жесткие требования, чем к лодочному мотору, а к последнему значительно больше, чем к ручной тачке. При обычных измерениях ограничиваются доверительной вероятностью 0,90 или 0,95. Для любой величины доверительного интервала (выраженного в долях s ) по формуле Гаусса может быть просчитана соответствующая доверительная вероятность. Эти вычисления проделаны и сведены в таблицу, имеющуюся практически во всей литературе по теории вероятности. На рис. 3 представлены значения надежности a при величине доверительного интервала ±s, ±2s, ±3s. Эти значения доверительной вероятности рекомендуется запомнить.
По рис. 3 видно, что величина абсолютной погрешности Dx может быть представлена в виде К×sа, где К некоторый численный коэффициент, зависящий от надежности a. Однако это справедливо лишь для большого (бесконечного) числа n. При малых n этим коэффициентом пользоваться нельзя, т.к. величина sа неизвестна. Для того, чтобы получить оценки границ доверительного интервала при малом n вводится новый коэффициент ta. Этот коэффициент предложен английским математиком и химиком В.С. Госсетом, публиковавшим свои работы под псевдонимом ² Стьюдент ².
Рис. 3. Значения надежности a при различных значениях Dx/s
И коэффициент ta назвали коэффициентом Стьюдента. Коэффициент Стьюдента
отражает распределение случайной величины t = ![]()
![]() при
различном n. При n®¥ ( практически при n ³ 20 ) распределение
Стьюдента переходит в нормальное распределение. Значения коэффициента Стьюдента
также приводятся практически во всей литературе по теории вероятности.
при
различном n. При n®¥ ( практически при n ³ 20 ) распределение
Стьюдента переходит в нормальное распределение. Значения коэффициента Стьюдента
также приводятся практически во всей литературе по теории вероятности.
Зная величину ta можно определить величину абсолютной погрешности Dх = t×Sa . Следует отметить, что величина абсолютной погрешности еще не определяет точность измерений. Точность измерений характеризует относительная погрешность, равная отношению абсолютной погрешности Dx результата измерений к результату измерений а: ε = ± Dх / а. .
1.8. Обнаружение промахов
Если в ряду измерений встречаются результаты, резко отличающиеся от большей части ряда, то возникает вопрос принадлежности ² выскакивающих ² значений этому ряду измерений. Большие ошибки имеют малую вероятность возникновения. Поэтому следует объективно оценить, является ли данное измерение промахом ( тогда его исключают из ряда ) или же это результат случайного, но совершенно закономерного отклонения. Можно считать каждое измерение промахом, если вероятность случайного появления такого значения является достаточно малой.
Если известно точное значение s, то вероятность появления значения, отличающегося от среднеарифметического а более чем на 3s £ 0,003 и все измерения, отличающиеся от а на 3s ( и больше ) могут быть отброшены, как маловероятные.
Следует иметь в виду, что для совокупности измерений вероятность появления измерения ³ 3s от а всегда больше 0,003. Действительно, вероятность того, что результат каждого измерения не будет отличаться от истинного более чем 3s составляет 1- 0,003 = 0,997. Вероятность того, что все n измерений не будут отличаться от среднего более чем на 3s по правилу умножения вероятностей составит ( 1 - 0,003 )n. Для не слишком большого n
(1 - 0,003)n » 1 - 0,003×n.
Это значит, что вероятность того, что из 10 измерений хотя бы одно будет случайно отличаться от среднего более чем на 3s будет уже не 0,003, а 0,03 или 3%. А при 100 измерениях вероятность такого события составит уже около 30%.
Обычно число измерений не очень велико. При этом точное значение s не известно, следовательно, отбрасывать измерения, отличающиеся от среднего более чем на 3s, нельзя.
Для оценки вероятности b случайного появления ²выскакивающих² значений в ряду n измерений составлены соответствующие таблицы.
Для применения таблицы вычисляется среднее арифметическое а и средняя квадратичная погрешность Sn из всех измерений, включая и подозреваемое значение аk. Затем вычисляется уклонение подозреваемого значения аk от среднего арифметического в долях среднеквадратичной ошибки
Vмакс = 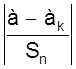 .
.![]()
По таблице определяется какой вероятности b соответствует полученное значение Vмакс.
Если вероятность появления данного измерения в ряду лежит в диапазоне 0,1 > b > 0,01, то представляется одинаково правильным - оставить это измерение или отбросить. В случае же, когда b выходит за указанные пределы, вопрос об отбрасывании решается практически однозначно. Решая вопрос об отбрасывании полезно посмотреть, как сильно оно меняет окончательный результат по а и Sn.
1.9. Ошибки косвенных измерений
Часто измеряется не непосредственно интересующая нас величина, а другая, зависящая от нее некоторым образом. Например, при резании металлов часто непосредственно измеряются деформации, ЭДС, по которым судят о возникающих силах и температурах. При этом также необходимо оценить ошибку измерения.
При косвенных измерениях значение y измеряемой величины находят по некоторой формуле
y = ¦ (х1, х2, ... , хm),
где x1, x2, ... xm - средние арифметические измеряемые (непосредственно) величины. Рассмотрим функцию общего вида
y = ¦ (х1, х2, ... , хm)
где x1, x2, ... , xm - независимые переменные, для определения которых производятся n прямых независимых измерений по каждой xi.
Обозначим значения переменных через среднее значение и отклонения
y ± Dy = ¦ (x1 ± Dx1, x2 ± Dx2, ... , xm ± Dxm).
Эту функцию представим рядом Тейлора, ограничив его первыми членами ряда ( принимая Dxi << xi )
y ± Dy
= ¦(х1,
х2, ... , хn) ± 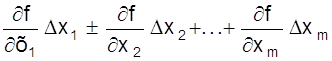 ,
,![]()
где
![]() - производная функции по xi, взятая в точке xi.
- производная функции по xi, взятая в точке xi.
Учитывая, что y = ¦ (x1, x2, ... , xm) получаем
Dy = 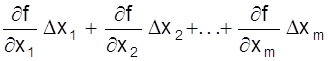 .
.
Чтобы учесть погрешности Dxi всех n опытов целесообразно использовать средние квадратические оценки ( D xi )2, так как Dxi = 0.
Возведем в квадрат левую и правую части уравнения и разделим на n
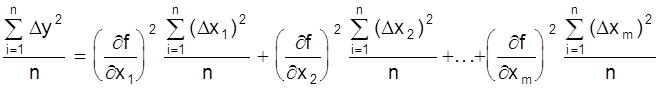 .
.
Здесь суммы удвоенных произведений типа
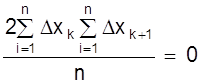
![]()
согласно четвертому свойству случайных ошибок ( Dxi = 0 ).
Тогда в левой и правой частях имеем среднеквадратические погрешности функции и аргументов
S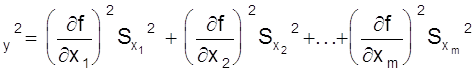 .
.
Пример. При тарировке динамометра было получено уравнение зависимости силы от отклонения l луча осциллографа вида P = 25 l. Точность измерения отклонения D l = 1 мм. Тогда
DP = ![]() .
.
В качестве меры точности лучше выступает не абсолютная, а относительная погрешность.
ε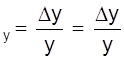 .
.
Рассмотрим ее определение на примере. Пусть
y = cx1a×x2b×x3g.
Тогда
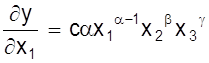 ;
;
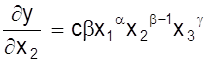 ;
;
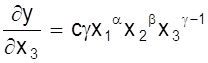 .
.
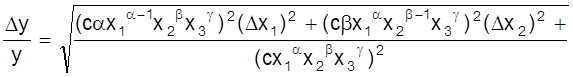
![]()
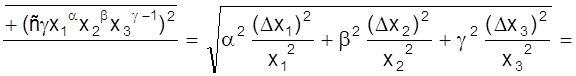
= ![]() .
.
Аналогично можно определить относительную погрешность и при других зависимостях. Зная относительную погрешность, можно определить и абсолютное ее значение:
Dy = y×εy.
1.10. Правила округления чисел
Величина погрешности результата измерений физической величины дает представление о том, какие цифры в числовом значении измеряемой величины сомнительны. Поэтому результаты измерений следует округлять перед тем, как производить с ними дальнейшие вычисления.
Округлять числовое значение результата измерений следует в соответствии с числовым разрядом значащей цифры погрешности. При этом выполняют общие правила округления.
Лишние цифры в целых числах заменяются нулями, а в десятичных дробях отбрасываются ( как и лишние нули ). Например, если погрешность измерения ± 0,001 мм, то результат 1,07005 округляется до 1,070.
Если первая из изменяемых нулями и отбрасываемых цифр меньше 5, остающиеся цифры не изменяются. Например, число 148935, точность измерения ± 50, округление: 148900.
Если первая из заменяемых нулями или отбрасываемых цифр равна 5, а за ней не следует никаких цифр или идут нули, то округление производится до ближайшего четного числа. Например, число 123,50 округляется до 124.
Если первая из заменяемых нулями или отбрасываемых цифр больше 5 или равна 5, но за ней следует значащая цифра, то последняя остающаяся цифра увеличивается на единицу. Например, число 6783,6 округляется до 6784.
1.11. Порядок обработки результатов измерений
При практической обработке результатов измерений можно последовательно выполнить следующие операции:
1. Записать результаты измерений;
2. Вычислить среднее значение из n измерений
а = 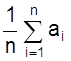
3. Определить погрешности отдельных измерений Vi = а - аi;
4. Вычислить квадраты погрешностей отдельных измерений Vi 2;
5. Если несколько измерений резко отличаются по своим значениям от остальных измерений, то следует проверить не являются ли они промахом. При исключении одного или нескольких измерений п.п.1...4 повторить;
6. Определяется средняя квадратичная погрешность результата серии измерений
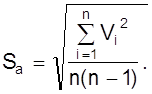
7. Задается значение надежности a;
8. Определяется коэффициент Стьюдента ta (n) для выбранной надежности a и числа проведенных измерений n;
9. Находятся границы доверительного интервала
Dх = ta (n)×Sa
10. Если величина погрешности результата измерений (п.9) окажется сравнимой с величиной d погрешности прибора, то в качестве границы доверительного интервала следует взять величину
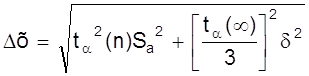 .
.
11. Записать окончательный результат
X = a ± Dx ;
12. Оценить относительную погрешность результата серии измерений
ε = 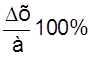 .
.![]()
1.12. Обработка результатов измерений диаметра цилиндра
Микрометром было сделано десять замеров диаметра цилиндра. Цена деления микрометра 0,01 мм. Определить диаметр цилиндра с надежностью a = 0,95 и a = 0,99. Оценить влияние числа замеров на точность получаемого результата.
аi: 14,85; 14,80; 14,84; 14,81; 14,79;
14,81; 14,80; 14,85; 14,84; 14,80.
1. Для первых пяти измерений определим среднеарифметическое значение и границы доверительного интервала. Для удобства расчетов выберем произвольное число ао удобное для расчетов (ао = 14,80 мм) и определим разности (аi - ао) и квадраты этих разностей. Результаты сведены в таблицу.
| i |
аi, мм |
аi - ао, мм |
(аi - ао)2, мм2 |
| 1 | 14, 85 | 0, 05 | 0, 0025 |
| 2 | 14, 80 | 0, 00 | 0, 0000 |
| 3 | 14, 84 | 0, 04 | 0, 0016 |
| 4 | 14, 81 | 0, 01 | 0, 0001 |
| 5 | 14, 79 | -0, 01 | 0, 0001 |
|
|
0, 09 |
0, 0043 |
|
Найдем среднее значение а и среднеквадратичное отклонение Sа:
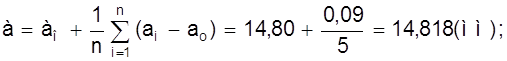
а - ао = 0, 018 мм;
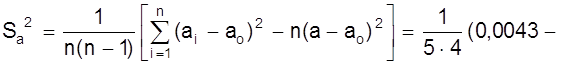
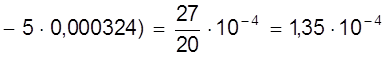
![]() ( мм2 );
( мм2 );
![]() ( мм ).
( мм ).
Для надежности a = 0,95 и n = 5 ta = 2,78. Абсолютная погрешность измерения Dх:
Dх = ta× Sа = 2,78 × 0,0116 = 0,0322 мм.
Результат измерения можно представить в виде
(14,818 - 0,032) мм £ а £ (14,818 + 0,032) мм
или сохраняя в величине погрешности одну значащую цифру
(14,82 - 0,03) мм £ а £ (14,82 + 0,03) мм,
т.е. 14,79 мм £ а £ 14,85 мм или а = (14,82 ± 0,03) мм.
Относительная погрешность
εа = 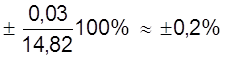 .
.
Теперь найдем абсолютную и относительную погрешность этих измерений при a = 0,99.
В этом случае ta = 4,60. Тогда
Dх = ta×Sa = 4,60×1,16×10-2 = 5,34×10-2 ( мм ).
Следовательно а = (14,82 ± 0,05) мм
εа = 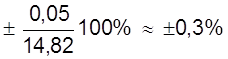 .
.
Видно, что с увеличением надежности границы доверительного интервала возросли, а точность результата уменьшилась.
2. Проведем расчет погрешностей для этих же пяти измерений, незаконно
полагая, что s2 = S2n (что при n = 5 ошибочно). Для этого
используем распределение Гаусса (а не Стюарта). При a = 0,95 ka = 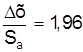 .
.
Это дает возможность определить
Dх = ka×Sa = 1,96×1,16×10-2 » 2×10-2 ( мм ),
т.е. погрешность получилась меньше примерно на 30%. Если по этой величине погрешности определить величину надежности при ta = ka, то из таблицы коэффициентов Стьюдента получим a < 0,90 вместо заданной a = 0,95. Следовательно при малом числе измерений n применение закона нормального распределения с s2 = S2n вместо распределения Стьюдента приводит к уменьшению надежности результата измерений.
3. Найдем средние значения и погрешности следующих пяти измерений
| i |
аi, мм |
аi - ао, мм |
(аi - ао)2, мм2 |
| 1 | 14, 81 | 0, 01 | 0, 0001 |
| 2 | 14, 80 | 0, 00 | 0 |
| 3 | 14, 85 | 0, 05 | 0, 0025 |
| 4 | 14, 84 | 0, 04 | 0, 0016 |
| 5 | 14, 80 | 0, 00 | 0 |
|
|
0, 10 | 0, 0042 | |
ао = 14, 80 мм;
а = ао +
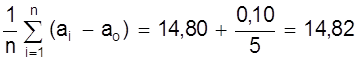 ( мм );
( мм );
а - ао = 0, 02 мм;
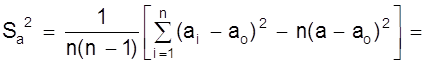
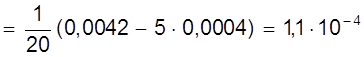 ( мм2 );
( мм2 );
Sa = 1, 05×10-2 мм.
При a = 0,95:
Dх = ta×Sa = ± 2,78×1,05×10-2 = 2,92×10-2 ( мм );
εа = ![]() ;
;
Х = 14, 82 ± 0, 03 мм.
При a = 0,99:
Dх = ± 4,60×1,05×10-2 » 5×10-2 ( мм );
εа = ± ![]()
Х = 14, 82 ± 0,05 мм.
Результаты практически не отличаются, от результатов полученных из первой серии.
4. Найдем теперь погрешность результата всей серии из десяти измерений. В
этом случае ![]() (мм);
(мм); ![]() (мм2).
(мм2).
Эти величины получаются суммированием последних строк из таблиц частных серий.
ао = 14, 80 мм;
а = ао
+ 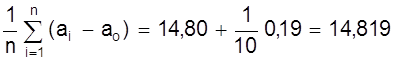 ( мм );
( мм );
а - ао = 0, 019 мм.
Sa2 = 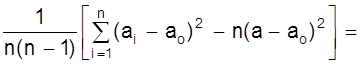
=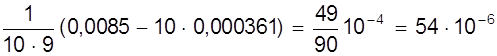 ( мм2 );
( мм2 );
Sa = 7, 35×10-3 мм.
При a = 0,95 имеем
Dх = ta×Sa = ± 2,26×7,35×10-3 = ± 1,7×10-2 ( мм );
εа = 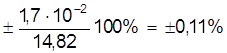 ;
;
а = 14, 819 ± 0, 017 мм.
При a = 0,99 получаем
Dх = ta×Sa = ± 3,25×7,35×10-2 = ± 2,4×10-2 ( мм );
εа = 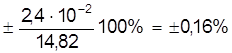 ;
;
а = 14, 819 ± 0, 024 мм.
Видно, что абсолютная и относительная погрешность результата десяти измерений стали почти в два раза меньше погрешностей пяти измерений.
Применение нормального распределения с s2 = S2n дает в случае a = 0,95 ka = 1,96 и Dх = 1,4 × 10-2 мм, а величина надежности понижается до 0,91; в случае a = 0,99 получаем ka = 2,58 и Dх = 1,9 × 10-2 мм, а величина надежности понижается до a = 0,97.
Как видно, с ростом числа измерений различие между результатами, вычислениями по распределению Стьюдента и по нормальному распределению уменьшается.
Контрольные вопросы
1. Цель математической обработки результатов эксперимента;
2. Виды измерений;
3. Типы ошибок измерения;
4. Свойства случайных ошибок;
5. Почему среднеарифметическое значение случайной величины при нормальном законе ее распределения является вероятнейшим значением?
6. Что такое истинная абсолютная и вероятнейшая ошибки отдельного измерения?
7. Что такое доверительный интервал случайной величины?
8. Что такое уровень значимости (надежности) серии измерений?
9. Геометрический смысл уровня значимости;
10. Почему при малом числе опытов нельзя погрешность измерений представить в виде Dх = ± Ksа?
11. Что является критерием “случайности” большого отклонения измеряемой величины?
12. Чем определяется величина случайной ошибки косвенных измерений?
13. Чем определяется точность числовой записи случайной величины?
2. ЗАКОНЫ РАСПРЕДЕЛЕНИЯ СЛУЧАЙНЫХ ВЕЛИЧИН
При характеристике случайных величин недостаточно указать их возможные значения. Необходимо еще знать насколько часто возникают различные значения этой величины. Это характеризуется вероятностью p отдельных ее значений.
Соотношение, устанавливающее связь между значениями случайной величины и вероятностями этих значений, называют законом распределения случайной величины. Различают интегральный и дифференциальный законы распределения.
2.1. Виды случайных величин и законы их распределения
Под случайной величиной понимается величина, принимающая в результате опыта какое либо числовое или качественное значение.
Случайная величина, принимающая конечное число или последовательность различных значений, называется дискретной случайной величиной. Случайная величина, принимающая все значения из некоторого интервала, называется непрерывной случайной величиной.
Под интегральным законом распределения (или функцией распределения) F (х) случайной величины Х понимают вероятность p того, что случайная величина Х не превысит некоторого ее значения х
F (х) = p (Х < х).
Основным свойством интегрального распределения является монотонное не убывание в ограниченном диапазоне [ 0; 1 ].
Действительно, если х1 и х2 некоторые значения случайной величины Х. Причем х2 > х1, то очевидно, что событие p (Х < х2) ³ p (Х < х1), т.к. между значениями х1 и х2 могут быть и промежуточные. Из определения интегрального закона следует, что F (х2) ³ F (х1), что говорит о монотонном не убывании функции. Очевидно также, что
F (- ¥) = p (Х < - ¥) = 0;
Þ F (¥) - F (- ¥) = 1,
F (+ ¥) = p (Х < ¥) = 1;
т.е. F (х) изменяется в диапазоне от 0 до 1.
Закон распределения дискретной случайной величины может быть задан таблицей или ступенчатой функцией (рис. 4)
Рис. 4. Интегральный закон распределения
дискретной случайной величины
Для дискретной случайной величины
F (x) = P (X < x) = P (-¥ < X < x) = 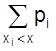 ,
,
![]() где суммирование распространяется на хi < х. В промежутке между двумя
последовательными значениями Х функция F (х) постоянна.
При переходе аргумента х через значение хi
F (х) скачком возрастает на величину p (Х = хi).
где суммирование распространяется на хi < х. В промежутке между двумя
последовательными значениями Х функция F (х) постоянна.
При переходе аргумента х через значение хi
F (х) скачком возрастает на величину p (Х = хi).
Рассмотрим p (х1 £ Х < х2). Если х2 > х1, то очевидно, что
p (Х < х2) = p (Х < х1) + p (х1 £ Х < х2).
Тогда
p (х1 £ Х < х2) = p (Х < х2) - p (Х < х1) = F (х2) - F (х1),
т.е. вероятность попадания случайной величины в интервал [х1; х2) равен разности значений интегральной функции граничных точек.
Последнее условие можно использовать для нахождения вероятности p (Х = х1) для непрерывной случайной величины. Для этого рассмотрим предел
p (X = x1)
= ![]() ,
,
т.е. если закон распределения случайной величины есть функция непрерывная, то вероятность того, что случайная величина примет заранее заданное значение, равна нулю.
Здесь видно различие между дискретными и непрерывными случайными величинами. Для дискретных случайных величин, для каждого значения случайной величины существует своя вероятность. И для него справедливо утверждение: событие, вероятность которого равна нулю, невозможно. Для непрерывной случайной величины это утверждение неверно. Как показано, вероятность того, что Х = х1 ( где х1- заранее выбранное число) равна нулю, это событие не является невозможным.
Рассмотрим непрерывную случайную величину Х, интегральный закон которой предполагается непрерывным и дифференцируемым. Функцию
¦ (х) = F¢ (õ)
называют дифференциальным законом распределения или плотностью вероятности случайной величины Х. Из определения производной можно записать
¦ (x) = F¢ (x)
= 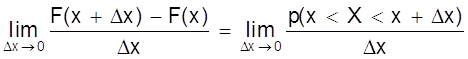 ,
,
т.е. плотность вероятности случайной величины Х в точке х равна пределу отношения вероятности попадания величины Х в интервал (х; х + Dх) к Dх, когда Dх стремится к нулю.
Используя понятия интегральной функции распределения и определенного интеграла можно записать
¦
(x) = F¢ (x) или
F (x) = p (x1 <
X < x2) = 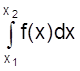 .
.
Это соотношение имеет простое геометрическое толкование (рис. 5).
Если 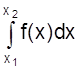 определяет заштрихованную
область в соответствующих пределах, то
определяет заштрихованную
область в соответствующих пределах, то
p (х < Х < х + Dх) » ¦ (х) Dх.
Рис. 5. Геометрический смысл дифференциальной функции распределения
Из свойств интегрального распределения следует
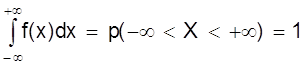 .
.
Зная дифференциальный закон распределения можно определить интегральный закон распределения
F (x) = 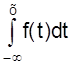 .
.
2.2. Числовые характеристики случайных величин, заданных своими распределениями
Основными характеристиками случайной величины, заданной своими распределениями, является математическое ожидание ( или среднее значение ) и дисперсия.
Математическое ожидание случайной величины является центром ее распределения. Дисперсия характеризует отклонение случайной величины от ее среднего значения.
Если Х дискретная
случайная величина, значения хi которой принимают с вероятностью
pi, так, что 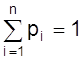 , то
математическое ожидание М (Х) случайной величины Х определяется равенством
, то
математическое ожидание М (Х) случайной величины Х определяется равенством
M (X) =  ,
,
т.е. суммой произведений всех ее возможных значений на соответствующие вероятности.
Математическим ожиданием непрерывной случайной величины является аналог его дискретного выражения
M (X)
= 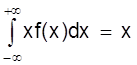 .
.
Действительно, все значения в интервале (х; х + Dх) можно считать примерно равными х, а вероятность таких значений равна ¦ (х) dx (см. ранее). Поэтому значения хi дискретного распределения заменяются х, а вероятности pi - на ¦ (х) dx, а сумма заменяется интегралом.
Дисперсией или рассеянием случайной величины Х называется математическое ожидание квадрата разности случайной величины и ее математического ожидания.
D (Х) = М [Х - М (Х)]2 = М (Х - х)2 = s2 (х)
Если случайная величина Х дискретна и принимает значения хi с вероятностями pi, то случайная величина (Х - х)2 принимает значения (хi - х)2 с вероятностями Рi. Поэтому для дискретной случайной величины имеем
D (X)
= 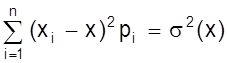 .
.
Аналогично для непрерывной случайной величины получаем
D (X)
= 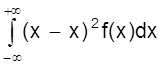 .
.
Чем меньше величина дисперсии, тем лучше значения случайной величины характеризуются ее математическим ожиданием.
2.3. Основные дискретные и непрерывные законы распределения
Как отмечалось ранее, очень часто случайная величина распределена по нормальному закону. Но существуют и другие распределения, имеющие практическое значение. Рассмотрим некоторые из них по условиям возникновения и основным параметрам их характеризующим.
1. Равномерное распределение вероятностей.
Пусть плотность вероятности А равна нулю всюду, кроме интервала (a; b), на котором она постоянна (рис. 6). Тогда можно записать
p (a < X < b) = 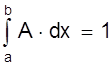
![]() A =
A = 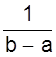 .
.
Рис. 6. Дифференциальный и интегральный законы
равномерного распределения
Тогда дифференциальный закон равномерного распределения определяется
¦ (x) = 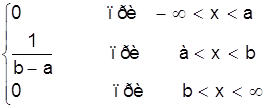
![]()
Интегральный закон распределения
F (x)
= 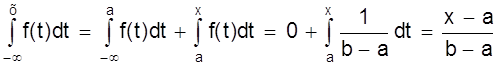 .
.
При х ³ b имеем
F (x) = 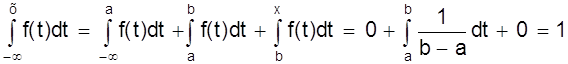
Таким образом интегральный закон равномерного распределения задается (рис. 6)
F (x) = 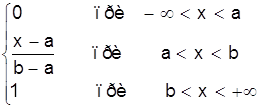
Основные характеристики распределения
М
(X) = 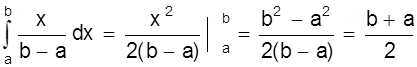 ;
;
D(X) = 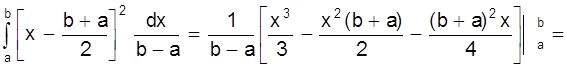
= 
= 
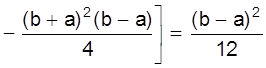 .
.![]()
2. Биноминальное распределение
Пусть при некотором испытании событие А может наступить или не произойти (А). Обозначим вероятность А через р, а А через q = 1 -р ( других итогов испытания нет ). Тогда исходами двух последовательных независимых испытаний и их вероятностью будут:
АА - р2; АА - рq; АА - qр; АА - q2.
Отсюда видно, что двукратное появление события А равно р2, вероятность однократного появления - 2 рq, а вероятность того, что А не наступит ни разу - q2. Эти результаты единственно возможные и поэтому
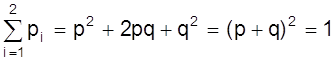 .
.
Это рассуждение можно перенести на любое число испытаний.
Например, при трех испытаниях получим
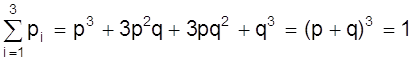 .
.
Подсчитаем вероятность того, что при n испытаниях событие А появится m раз. Это может произойти, например, в последовательности
![]()
Ясно, что вероятность равна рmqn-m.
Но m событий А может быть и в другом сочетании. Число всех
возможных сочетаний из n элементов по m (количество
событий А) равно числу сочетаний ![]() .
Используя теорему сложения вероятностей получаем общую вероятность Рm,n наступления m событий А из n испытаний
.
Используя теорему сложения вероятностей получаем общую вероятность Рm,n наступления m событий А из n испытаний
Pm,n = 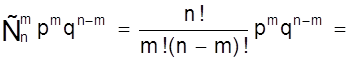
= 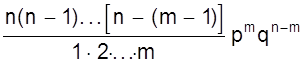 .
.
Из этой формулы видно, что вероятности Рm,n для различного исхода испытаний (появление или не появление определенного результата А) определяется
pn +
npn-1q + 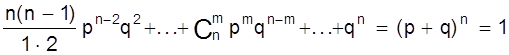 .
.
Коэффициенты перед вероятностями р, q являются биноминальными коэффициентами, а общая вероятность представляет слагаемые в разложении бинома ( р + q )n. Поэтому закон распределения случайной величины Х, в котором вероятность наступления событий А определяется коэффициентами бинома, называется биноминальным распределением дискретной случайной величины. Этот закон может быть задан в виде таблицы 1.
Таблица 1
Биноминальный закон распределения
|
хi |
0 |
1 |
2 |
... |
m |
... |
n |
|
|
pi |
qn |
npqn-1 |
|
... |
|
... |
pn |
|
Биномиальные коэффициенты удобно получать с помощью треугольника Паскаля.
1 n = 0
1 1 n = 1
1 2 1 n = 2
1 3 3 1 n = 3
1 4 6 4 1 n = 4
1 5 10 10 5 1 n = 5
Все строки треугольника ( начинающегося с единицы ) начинаются и заканчиваются единицей. Промежуточные числа получаются сложением соседних чисел вышестоящей строки. Числа, стоящие в одной строке, являются биноминальными коэффициентами соответствующей степени.
Из описания биномиального распределения становится ясно, что область его действия там, где возможно многократное проведение испытаний с известной вероятностью.
На рис. 7 представлен биномиальный закон распределения.
Рис. 7. Биномиальный закон распределения
Определим основные характеристики этого распределения.
Математическое ожидание
М (Х) = 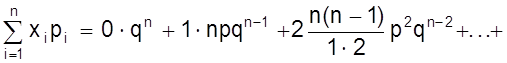
+ 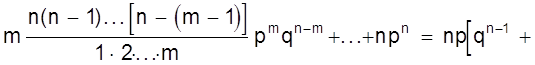
+ 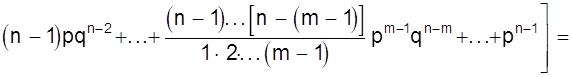
= np (q + p)n-1 = np.
Дисперсия распределения может быть определена из общего выражения
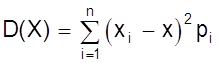 ,
,
но это приводит к громоздким вычислениям. В то же время случайная величина Х принимает в каждом опыте только два значения: 1, если событие А произошло и 0, если оно не произошло с вероятностями, соответственно, р или q. Тогда математическое ожидание одного опыта определится
М (Х1) = 0×q + 1×р = р = х
и соответственно дисперсия одного опыта
D (Х1) = (0 - р)2×q + (1 - р)2×р = р2q + q2р = рq (р + q) = рq.
Тогда дисперсия всех n опытов составит
D (X) = n×p×q.
3. Закон Пуассона
В случае малых р ( или, наоборот, близких к 1 ) биноминальный закон распределения можно преобразовать следующим образом
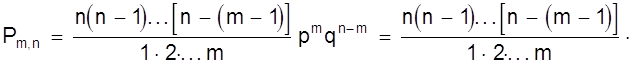
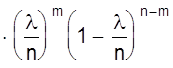 ,
,
где  .
.
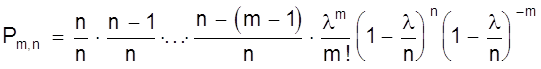 .
.
Определим предел Рm,n при n ® ¥ и постоянном m. Тогда пределы
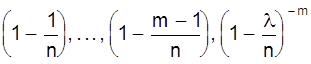 равны единице, а
равны единице, а 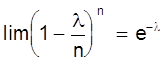 .
.
Окончательно имеем
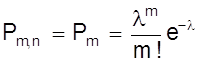 .
.
Это распределение называется законом Пуассона, где l - интенсивность распределения. Используется в задачах с редкими событиями. На рис. 8 представлена схема вероятностей, распределенных по закону Пуассона.
Рис. 8. Закон распределения Пуассона
Определим его основные характеристики и смысл величины l.
Запишем закон распределения в виде таблицы.
|
õi |
0 |
1 |
2 |
... |
m |
... |
|
pi |
e-l |
|
|
... |
|
... |
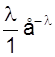
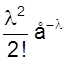
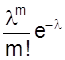
M (X) = 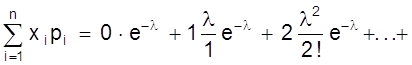
+ 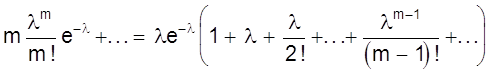 .
.
Выражение в скобках есть разложение функции еl в ряд Маклорена.
Поэтому
М (Х) = lе-lеl = l.
Не рассматривая вывод отметим, что
D (Х) = l,
т.е. дисперсия равна математическому ожиданию.
Рассмотренные виды распределений случайной величины, конечно, не исчерпывают всех существующих распределений. Можно назвать еще несколько: распределение Бернулли, экспоненциальное распределение, гамма - распределение, распределение Вейбула, гипергеометрические распределения и др. При определенных условиях и параметрах один вид распределения может переходить в другой. Поэтому при решении практических задач по законам распределения случайных величин следует обращаться к специальной литературе.
2.4. Понятие статистической гипотезы и статистического критерия
Статистической гипотезой называют любое утверждение о виде или свойствах распределения наблюдаемых в эксперименте случайных величин. Такие утверждения можно делать на основе теоретических соображений или статистических исследований других наблюдений. Например, при многократном измерении некоторой физической величины, точное значение Х которой не известно, но в процессе измерений оно меняется. На результат измерений влияют многие случайные факторы, поэтому результат i - го измерения можно записать в виде аi = Х + εi, где εi - случайная погрешность измерения. Если εi складывается из большого числа ошибок, каждая из которых не велика, то на основании центральной предельной теоремы можно предположить, что случайные величины аi имеют нормальное распределение. Такое предположение является статистической гипотезой о виде распределения наблюдаемой случайной величины.
Если для исследуемого явления сформулирована та или иная гипотеза ( обычно ее называют основной или нулевой гипотезой и обозначают символом Но ), то задача состоит в том, чтобы сформулировать правило, которое позволяло бы по результатам наблюдений принять или отклонить эту гипотезу. Правило, согласно которому проверяемая гипотеза Но принимается или отвергается, называется статистическим критерием проверки гипотезы Но .
Наиболее распространены такие статистические гипотезы, как:
а) вида распределения;
б) однородности нескольких серий независимых результатов;
в) случайности результатов эксперимента и т.п.
Статистический критерий проверки гипотезы Но служит для определения возможного отклонения от основной гипотезы. Характер отклонений может быть различным. Если критерий ²улавливает² любые отклонения от Но, то такой критерий называют универсальным или критерием согласия. Существуют критерии, которые выявляют отклонения от заданного вида, это узко направленные критерии.
Выбор правила проверки гипотезы Но эквивалентен заданию критической области х1, при попадании в которую переменной х гипотеза Но отвергается. Критерий, определяемый критической областью х1 называют критерием х1.
В процессе проверки гипотезы Но можно прийти к правильному решению или совершить ошибку первого рода - отклонить Но когда она верна, или ошибку второго рода - принять Но, когда она ложна. Иными словами, ошибка первого рода имеет место, если точка х попадает в критическую область х1, в то время как верна нулевая гипотеза Но, а ошибка второго рода - когда х Î хо, но гипотеза Но ложна.
Желательно провести проверку гипотезы так, чтобы свести к минимуму вероятности обоих ошибок. Однако при данном числе испытаний n в общем случае невозможно одновременно обе эти вероятности сделать как угодно малыми. Поэтому наиболее рационально выбирать критическую область следующим образом: при заданном числе испытаний n устанавливается граница для вероятности ошибки первого рода и при этом выбирается та критическая область х1, для которой вероятность ошибки второго рода минимальна.
2.5. Вероятности ошибок первого и второго рода
Рассмотрим станок, который может работать только в одном из двух состояний. Если он работает в налаженном режиме, то для интересующего нас признака качества, например, длины или диаметра заготовки, имеет место нормальное распределение при работе как в налаженном так и в разлаженном режиме. Оба режима отличаются только уровнем настройки процесса по математическому ожиданию ( М(х) = 10 и 11, соответственно в налаженном и разлаженном режиме ), в то время как дисперсии в обоих случаях составляют s2 = 4.
Проверить нужно нулевую гипотезу, в соответствии с которой М(х) = 10, против альтернативы ( в данном случае единственной ) М(х) = 11. Конкурирующую гипотезу обозначим Н1. Тогда Но: М(х) = 10; Н1: М(х) = 11.
Необходимо по результатам выборки определить в каком из состояний работает станок. Примем объем выборки n из потенциально бесконечной генеральной совокупности. В качестве контрольной величины возьмем выборочное среднее Хn. На рис. 9 изображены плотности распределения Хn для n = 25 и n = 4.
Для формулировки критерия необходимо разделить область изменения контрольной величины (х) на критическую область отклонения гипотезы Но ( принятия Н1 ) и область принятия гипотезы Но. Для этого необходимо выбрать число К, такое, что 10 < К < 11, и интервал ( -¥; К ] рассматривать как область принятия гипотезы Но, а интервал [ К; ¥ ) - как область отклонения гипотезы Но. По рис. 9 видно, что каждая реализация Х25 или Х4 возможна при верности любой из двух гипотез, но с различной вероятностью. На рис. 9 указаны вероятности совершения ошибки первого
Рис. 9. Плотности распределения двух гипотез при различном
объеме выборки и одинаковой дисперсии
рода a ( отклонения верной гипотезы Но ) и второго рода b ( принятие гипотезы Но, когда она не верна ). По рис. 9 также видно, что увеличение n ведет к уменьшению дисперсии распределения х и тем самым - к одновременному уменьшению вероятностей a и b. В соответствии с рис. 9 можно записать:
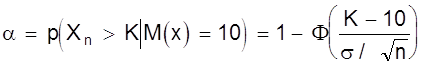 ;
;
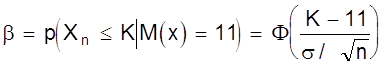 .
.
Эти два уравнения содержат четыре величины a, b, К, n. Задав две из четырех величин, можно определить две другие.
Например, при n = 25 и К = 10,4 определим:
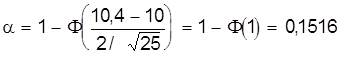 ;
;
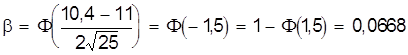 .
.
Если задаться величинами a и b, то можно определить величины К, n.
2.6. Проверка гипотезы вида закона распределения вероятностей
При проверке эксперимента закон распределения вероятностей случайных величин неизвестен и можно лишь предположительно судить о его виде . Выборочные оценки параметров распределения несут в себе случайные ошибки, искажающие истинный характер распределения. Поэтому после получения эмпирического распределения производится подбор теоретического закона распределения, пригодного для описания вероятностных свойств изучаемой случайной величины. Критерии подбора ( проверки гипотезы соответствия ) называют в статистике критериями согласия. Все они основаны на выборе допустимой меры расхождения между теоретическим распределением и выборочными данными.
Общую процедуру проверки гипотезы закона распределения можно представить в следующей последовательности:
1. По опытным данным строится эмпирическая кривая распределения вероятностей;
2. Определяются параметры эмпирического распределения ( в соответствии с его видом );
3. Выдвигается одна или несколько гипотез о функции плотности исследуемой случайной величины, исходя из внешнего вида эмпирической кривой, значений ее параметров, технических факторов, влияющих на ее вид;
4. Эмпирическая кривая выравнивается по одной или нескольким теоретическим кривым;
5. Проводится сравнение по одному или нескольким критериям согласия;
6. Выбирается теоретическая функция, дающая наилучшее согласование.
Поясним п. 4; 5. Определив по эмпирическим данным параметры распределения, подставляют их в теоретическую кривую закона распределения и рассчитывают вероятность середин интервалов эмпирического распределения. Умножив значение полученной вероятности на общее число опытов, получают теоретическое значение частот случайной величины, которые и определяют ²выровненную² кривую. Теперь можно найти вероятность того, что эмпирическая кривая соответствует выбранной теоретической, выбрав вероятность согласия ( уровень значимости ). Если результат расхождения не выйдет за принятый уровень значимости, то считают, что эмпирическое распределение согласуется с теоретическим. Если сравнение осуществляется с несколькими теоретическими законами, то окончательно принимать тот, который дает лучшее соответствие.
Чаще всего в качестве критериев согласия принимают критерий Пирсона ( c2 ) и критерий Колмогорова - Смирнова ( К - С - критерий ).
Критерий c2 является наиболее состоятельным при большом числе наблюдений. Он почти всегда опровергает неверную гипотезу, обеспечивает минимальную ошибку в принятии неверной гипотезы по сравнению
с другими критериями.
c2 = 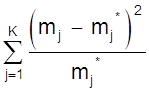 ,
,
где mj - наблюдаемая частота случайного события;
m*j - ожидаемая по принятому теоретическому закону распределения;
К - число интервалов случайной величины.
Затем определяется число степеней свободы l:
l = К - r - 1;
где К - число интервалов случайной величины;
r - число параметров теоретической функции распределения.
К - С - критерий лучше всего использовать в случае, если теоретические значения параметров распределения известны. При неизвестных параметрах его можно использовать, но он дает несколько завышенные результаты. При использовании этого критерия определяется величина
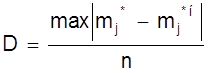 ,
,
где
mнj, m*нj - соответственно, накопленные наблюдаемые и ожидаемые
(теоретические) частоты;
n - число проведенных опытов.
То есть, в данном случае оценивается только максимальное отклонение накопленной частоты случайного события, возникающее в одном из диапазонов изменения случайной величины. Полученное значение коэффициента сравнивается с табличным для числа степеней свободы опыта и принятого уровня значимости результата. Если табличное значение коэффициента больше, то гипотеза о принятом законе распределения не отвергается.
Контрольные вопросы
1. Сущность непрерывной и дискретной случайной величины;
2. Сущность интегрального закона распределения случайной величины;
3. Сущность дифференциального закона распределения случайной величины;
4. Связь интегрального и дифференциального законов распределения;
5. Основные характеристики случайной величины, заданной своим распределением;
6. Назовите примеры законов распределения непрерывной и дискретной случайной величины;
7. Понятие статистической гипотезы и статистического критерия;
8. Назовите примеры статистических гипотез;
9. Сущность ошибок первого и второго рода;
10. Сущность проверки гипотезы вида закона распределения;
11. Принципиальное различие в критериях Пирсона и Колмогорова - Смирнова.
3. НАХОЖДЕНИЕ ИНТЕРПОЛИРУЮЩИХ КРИВЫХ
В первой части пособия рассматривались измерения той или иной физической величины, находящейся при проведении серии измерений в неизменном состоянии. Очень часто исследуемая величина меняется в соответствии с изменением условий опыта или времени. Цель эксперимента в этом случае состоит в нахождении функциональной зависимости, которая наилучшим образом описывает изменение интересующего нас параметра.
Следует понимать, что однозначно восстановить ( большей частью неизвестную ) функциональную зависимость между переменными невозможно даже в том случае, если бы переменные величины, полученные из опыта, не имели бы ошибки измерения. Тем более не следует ожидать, что это удастся сделать, имея экспериментальные данные, содержащие, по крайней мере, случайные ошибки измерений.
Поэтому математическая обработка результатов наблюдений не может ставить перед собой задачу разгадать истинный характер зависимости между переменными. Она позволяет лишь представить результаты опыта в виде наиболее простой формулы.
В зависимости от назначения этих формул существуют различные методы их получения, отличающиеся сложностью расчетных процедур и точностью получаемых решений.
3.1. Графический метод обработки результатов
Графический метод заключается в построении графика зависимости между исследуемыми величинами с последующим определением уравнения зависимости между ними.
Графики строят прежде всего в равномерных шкалах. Если характер связи между исследуемыми величинами неизвестен, то сначала проверяют совпадение экспериментальных точек с заданной кривой. Если предварительные сведения о характере уравнения отсутствуют, то первым этапом обработки данных является нахождение кривой, совпадающей с опытными точками. Эта задача решается методом подбора. Можно использовать эталон - кальку с предварительно вычерченным на ней семейством кривых с различными параметрами. Естественно, что масштаб кальки и эмпирической кривой должен быть одинаков.
Построенный по опытным данным отрезок кривой может совпадать с большим количеством различных кривых, проходящих достаточно близко к опытным точкам. В этом случае выбирают кривую с наиболее простым и удобным в использовании уравнением. Иногда эмпирическая кривая может иметь перегибы или состоять из отдельных ярко выраженных участков. Однако при этом необходимо определить координаты точек перехода от одной кривой к другой.
Уравнение зависимости между исследуемыми величинами при графическом методе просто определяется тогда, когда эмпирические точки достаточно хорошо совпадают с прямой линией, т.е. описываются уравнением y = ax + b, где a, b - коэффициенты, подлежащие определению.
Определение коэффициентов при графическом методе основано на ²способе натянутой нити². Нанеся результаты эксперимента на график (лучше, если он выполнен на миллиметровке), подбираем графическую прямую, ближе всего подходящую к нанесенным точкам. Выбрав положение прямой, определяем две произвольные точки на этой прямой (не обязательно являющиеся точками эксперимента), определяем их координаты (x1; y1), (х2; y2). И для определения коэффициентов а и b получаем два простых уравнения
ах1 + b = y1;
ах2 + b = y2.
На рис. 10 приведена иллюстрация этого метода. Точки - результаты, полученные в эксперименте. Прямая проведена на глаз как можно ближе к экспериментальным точкам. На прямой выбраны точки М (2; 4) и N (13; 10). Коэффициент а характеризует угол наклона прямой.
Поэтому
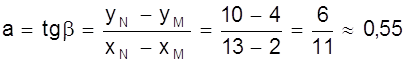
![]() .
.
Таким образом y = 0,55х + 2,9.
Рис. 10. Графический метод интерполяции
В случае, если экспериментальная зависимость имеет нелинейный характер, то графическим способом в системе координат с равномерными шкалами определить коэффициенты кривой затруднительно. Но достаточно большой класс нелинейных зависимостей путем замены переменных и графического изображения в функциональных шкалах можно привести к линейным и далее использовать способ натянутой нити.
3.2. Функциональные шкалы и их применение
Пусть функция y = ¦(х) непрерывна и монотонна на некотором промежутке [ a; b ]. Возьмем ось ОМ, на которой будет строиться шкала, выберем на ней точку начала отсчета О и установим масштаб m. Функциональная шкала строится следующим образом.
Разбив интервал [ а; b ] на равные части, вычисляем значение функции ¦(х) в каждой из точек деления и отложим на оси ОМ для каждой точки отрезок m¦(х). Получающаяся при этом точка снабжается отметкой х, т.е. откладывается в выбранном масштабе значение функции, а надписывается значение аргумента.
Иногда начало шкалы помещают в первую точку отсчета, т.е. точку с надписью а совмещают с 0. Тогда точка х будет находиться в конце отрезка m [ ¦(х) - ¦(а) ]. Полученная шкала позволяет судить о поведении функции на рассматриваемом участке: большие промежутки между отметками укажут, что функция изменяется быстрее, чем там, где эти промежутки малы.
Выбор масштаба m определяет длину шкалы. Чаще поступают наоборот: задаются длиной шкалы l и определяют масштаб.
![]() Þ
m =
Þ
m = 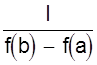 .
.
Пример. Построим
функциональную шкалу для функции y
= x2 на участке [ 1; 2 ]. Зададимся длиной шкалы l
= 12 см. Тогда m = ![]() см.
Разобьем отрезок [ 1; 2 ] на десять равных частей и
вычислим значения функции во всех точках деления. Совместим начало шкалы с
точкой отсчета х = 1. Результаты расчета сведены в табл. 2, а
функциональная шкала приведена на рис. 11.
см.
Разобьем отрезок [ 1; 2 ] на десять равных частей и
вычислим значения функции во всех точках деления. Совместим начало шкалы с
точкой отсчета х = 1. Результаты расчета сведены в табл. 2, а
функциональная шкала приведена на рис. 11.
Таблица 2
Расчет функциональной шкалы y = x2
| х | 1,0 | 1,1 | 1,2 | 1,3 | 1,4 | 1,5 | 1,6 | 1,7 | 1,8 | 1,9 | 2,0 |
|
х2 |
1,0 | 1,21 | 1,44 | 1,69 | 1,96 | 2,25 | 2,56 | 2,89 | 3,24 | 3,61 | 4,00 |
|
х2-1 |
0 | 0,21 | 0,44 | 0,69 | 0,96 | 1,25 | 1,56 | 1,89 | 2,24 | 2,26 | 3,00 |
|
4(х2-1) |
0 | 0,84 | 1,76 | 2,76 | 3,84 | 5,00 | 6,24 | 7,56 | 8,94 | 10,44 | 12,0 |
![]()
![]()
![]()
1,0 1,1 1,2 1,3 1,4 1,5 1,6 1,7 1,8 1,9 2,0
Рис. 11. Функциональная шкала y = x2
С помощью функциональных шкал графики многих функций могут быть преобразованы к прямолинейному виду.
Например, уравнение параболы y = x2. Если на оси OY нанести равномерную шкалу, а на оси OX1 шкалу квадратов х1 = х2, то получится сетка, где уравнение параболы имеет изображение прямой линии ( y = x1 ),
проходящей через начало координат.
Особенно часто используются различные логарифмические функции, с помощью которых можно ²выпрямлять² графики степенных и показательных функций. Например, y = aebx; lg y = (b lg å) х + lg a. Полагая lg y = y1, lg a = A, b lg e = B запишем исходное уравнение в виде y1 = А + Вх, откуда видно, что оставив равномерной шкалу х и построив логарифмическую шкалу y1, можно изобразить исходное уравнение прямой линией. Полученная координатная сетка называется полулогарифмической.
Очевидно, что такого рода преобразования возможны и в более общем случае. Всякая неявная функция, заданная соотношением вида
аj(х) + by(y) + с = 0,
где a, b, с - постоянные, будет изображаться прямой линией на функциональной сетке, где на оси ОХ построена шкала j(х), а на оси OY - шкала функции y(y). Естественно, что функции j(х) и y(y) должны удовлетворять условиям непрерывности и монотонности. В табл. 3 приведены преобразования для некоторых функций.
Таблица 3
Линеаризация некоторых функций
|
Исходная формула |
Преобразованная формула |
Замена переменных |
Линеаризованная формула |
|
y=axb |
lg y=b×lgx+lga |
lg y=y1 lg x=x1 lg a=a1 |
y1=bx1+a1 |
| y=a×lgx+b | ¾ |
lg x=x1 |
y=ax1+b |
|
y=ebx+k |
lg y=b×lge×x+k×lge |
lg y=y1 b×lg e=a k×lg e=k1 |
y1=ax+k1 |
|
y=aebx |
lg y=bx×lge+lga |
lg y=y1 b×lg e=b1 lg a=a1 |
y1=b1x+a1 |
|
y= |
¾ |
|
y=ax1+b |
|
y= |
|
|
y1=ax+b |
|
y= |
|
|
y1=bx1+a |
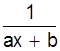
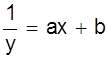
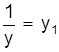
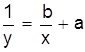
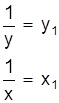
Из сказанного ясна роль функциональных сеток при обработке результатов эксперимента. Если результаты эксперимента располагаются вблизи кривой, то по имеющемуся ограниченному участку кривой трудно судить, какого типа функцией ее лучше всего приближать. Переведя полученные экспериментальные данные на функциональные сетки можно оценить на какой из них эти данные ближе всего подходят к прямой и, следовательно, какой функцией лучше всего описываются.
3.3. Аналитические методы обработки результатов
Графический метод обработки результатов обладает наглядностью, относительной простотой, однако его результаты содержат определенную субъективность и относительно низкую точность.
Аналитические методы лишены в какой - то степени указанных недостатков и позволяют получить результат для более широкого класса функций с большей точностью, чем графический метод.
Существуют различные аналитические методы получения параметров эмпирических кривых в зависимости от критерия, принятого при их получении. Рассмотрим некоторые из существующих способов.
3.3.1. Способ средней
Допустим, что имеется n сочетаний xi, yi, полученных при эксперименте. Даже в том случае, если между х и y теоретически установлена функциональная связь ( в данном случае предположим, что линейная ), то наблюдаемые значения yi будут отличаться от ахi + b вследствие наличия экспериментальных ошибок. Обозначим через Di соответствующую ошибку
Di = yi - axi - b (i = 1, 2, ..., n)
Если выбирать параметры а и b
так, чтобы для всех n наблюдений ошибки уравновешивались, т.е. 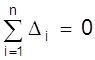 , то это привело бы нас к
одному уравнению, тогда как для нахождения двух коэффициентов (а, b) их
требуется два. Поэтому предположим, что уравновешивание происходит не только
для всех произведенных наблюдений в целом, но и для каждой группы, содержащей половину
( или почти половину ) всех наблюдений в отдельности.
, то это привело бы нас к
одному уравнению, тогда как для нахождения двух коэффициентов (а, b) их
требуется два. Поэтому предположим, что уравновешивание происходит не только
для всех произведенных наблюдений в целом, но и для каждой группы, содержащей половину
( или почти половину ) всех наблюдений в отдельности.
В этом случае можно прийти к системе уравнений
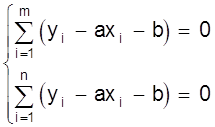 ,
,
где m - число наблюдений в первой группе.
Данную систему уравнений запишем теперь в виде
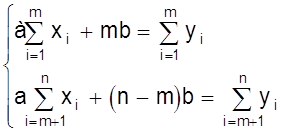 .
.
Изложенное показывает, что метод средних ²уравновешивает² положительные и отрицательные отклонения теоретической кривой от экспериментальных значений.
Пример.Используя данные рис. 10 определим коэффициенты а, b методом средней. Для этого семь измерений разделим на две группы m = 3 первых значений, n - m = 4 последующих
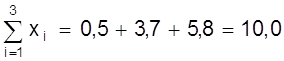 ;
; 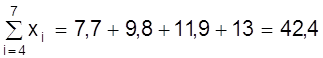 ;
;
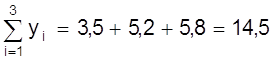 ;
; 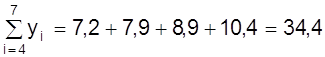 .
.
Получаем систему
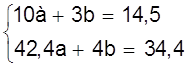
Решая систему находим
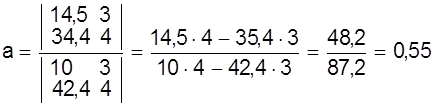 ;
;
b = 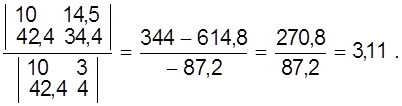
Таким образом способ средней дает прямую
y = 0,55х + 3,11.
В сравнении с графическим способом коэффициенты а совпадают и имеется различие в коэффициенте b.
3.3.2. Метод наименьших квадратов
В методе средних при определении коэффициентов уравнения использовалось условие равенства нулю алгебраической суммы отклонений результатов эксперимента от теоретической кривой ( в частном случае прямой ). Очевидно, что при этом Di могут быть значительной величины. Имеет значение только ²уравновешивание² положительных и отрицательных отклонений.
Поставим теперь задачу нахождения по результатам наблюдений наиболее вероятные значения неизвестных коэффициентов.
Предположим, что искомая зависимость y = ¦(х) существует. Тогда параметры этой линии необходимо выбрать таким образом, чтобы точки yi располагались по обе стороны кривой y = ¦(х) как можно ближе к последней. Предположим, что разброс точек yi относительно y = ¦(х) подчиняется закону нормального распределения. Тогда мерой разброса является дисперсия s2 или ее приближенное выражение - средний квадрат отклонений.
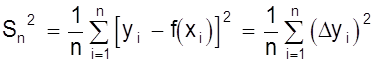 .
.
И требование минимального разброса будет удовлетворено, если минимизировать выражение ( Dyi )2. Как известно, необходимым условием того, что функция приобретает минимальное значение, является то, что ее первая производная ( или частные производные для функции многих переменных ) равна нулю. Применение метода наименьших квадратов имеет смысл, если число экспериментальных точек n больше числа определяемых коэффициентов.
Рассмотрим реализацию метода наименьших квадратов применительно к уравнению вида y = ax + b.
Для нахождения коэффициентов а, b искомой прямой необходимо минимизировать сумму квадратов расстояний Dyi по ординате от точки (хi; yi) до прямой ( см. рис. 12 ). Расстояния Dyi определятся
Dyi = yi - axi - b.
Рис. 12. К способу наименьших квадратов
Для минимизации 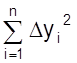 приравниваем к нулю
производные этой суммы по параметрам а, b:
приравниваем к нулю
производные этой суммы по параметрам а, b:
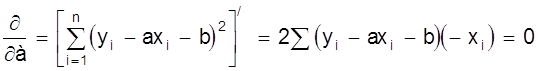 ;
;
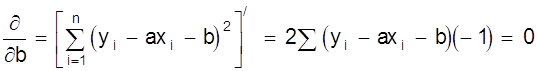 .
.
Преобразуем эту систему
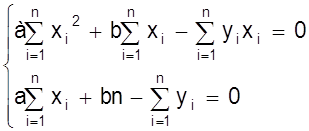
Получим систему нормальных уравнений метода наименьших квадратов.
Решая ее относительно а, b получаем:
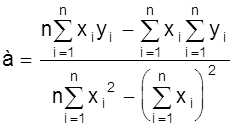 ;
; 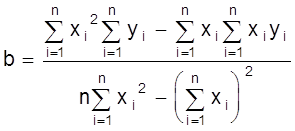 .
.
Вычисляя из n опытов необходимые суммы и производя указанные действия, получаем величину коэффициентов а, b.
Как видно, способ наименьших квадратов достаточно громоздок и при его применении широко используется вычислительная техника. Метод наименьших квадратов может использоваться и в случае нелинейных функций. Например, если определяются параметры квадратичной зависимости:
y = ах2 + bx + с,
то
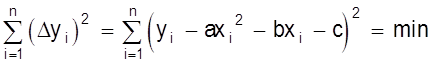 .
.
Дифференцируя это соотношение по а, b, с получаем систему нормальных уравнений:
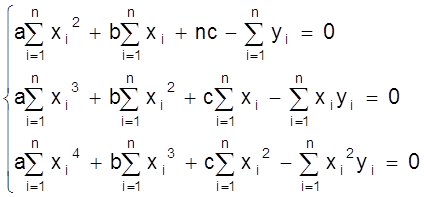
![]()
Из этой системы можно определить параметры а, b, с.
При использовании метода наименьших квадратов при других нелинейностях, удобнее будет линеаризовать исходные зависимости.
В табл. 4 приведены системы нормальных уравнений для некоторых исходных уравнений.
Таблица 4
Системы нормальных уравнений
|
Исходное уравнение |
Система нормальных уравнений |
|
y=axb |
|
| y=a×lgx+b |
|
|
y=eax+b |
|
|
y=aebx |
|
|
y= |
|
|
y= |
|
|
y= |
|
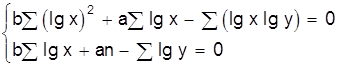
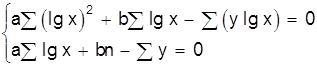
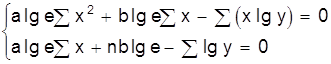
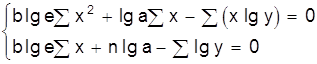
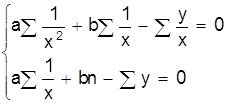
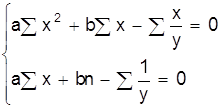
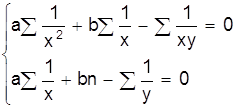
Примечания: 1. Величины х, y обозначают значения величин хi, yi в i-ом
опыте;
2. Знак S обозначают сумму величин от i = 1 до i = n, где n
- число равноточных измерений.
3.3.3. Интерполирование функций
Известно, что под интерполированием понимают отыскание значений функции, соответствующих промежуточным значениям аргумента, отсутствующим в таблице логарифмов, тригонометрических и др. функций.
В общем смысле можно сказать, что задача интерполирования обратна задаче табулирования функций. При интерполировании по таблице значений функции строится ее аналитическое выражение, т.е. по значениям функции yo, y1, ..., yn при значениях аргумента хо, х1, ..., хn определяется выражение неизвестной функции.
Понятно, что через данные точки ( даже большого числа ) можно провести множество различных кривых. Поэтому существует интерполирование в различных функциях F (х). Чаще всего требуют, чтобы функция F(х) была многочленом степени на единицу меньшей, чем число известных значений.
Таким образом, задачу интерполирования функций можно сформулировать следующим образом.
Для данных значений х º хо, х1, ..., хn и y º yo, y1, ..., yn найти многочлен y = F (х) степени n, удовлетворяющий условиям F (хо) = yo, F (х1) = y1, ..., F (хn) = yn. Точки хо, х1, ..., хn называют узлами интерполяции. Многочлен F (х) - интерполяционным многочленом , а формулы его построения - интерполяционными формулами.
Как видно из описания сущности интерполирования, в отличии от описанных ранее способов получения функций ( графического, метода средних, метода наименьших квадратов ), интерполяционный многочлен опишет кривую, проходящую точно через заданные точки.
3.3.4. Параболическое интерполирование
При параболическом интерполировании в качестве интерполяционного многочлена F (х) принимают многочлен n - ой степени вида
F (х) = ао + а1х + а2х2 + ... + аnxn.
Используя свойство прохождения функции F (х) через заданные точки для неизвестных коэффициентов аi можно составить n + 1 уравнений с n + 1 неизвестным:
ао + а1хо + а2хо2 + ... + аnхоn = yo;
ао + а1х1 + а2х12 + ... + аnх12 = y1;
....................................................
ао + а1хn + а2хn2 + ... + аnхn2 = yn.
Эта система имеет единственное решение, если значения хi отличны друг от друга. Понятно, что при большом n возникает сложность решения этой системы. Перед рассмотрением общего способа решения, рассмотрим простой пример.
Дано: хо = 0, х1 = 1, х2 = 2, yо = 1, y1 = 1, y2 = 3. Определить многочлен F (х).
Записывая многочлен F (х) в виде
F (х) = ао + а1х + а2х2
составим систему уравнений
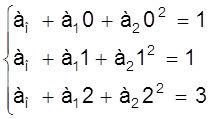 или
или 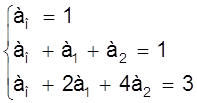
откуда ао = 1, а1 = - 1, а2 = 1 и интерполирующий многочлен имеет вид
F (х) = 1 - х + х2.
Теперь рассмотрим общий подход к отысканию интерполяционного многочлена F (х), не решением системы, а непосредственной записью.
Определим выражение для многочлена, принимающего в точке х = хо значение yо = 1, а в точках х = х1, х2, ..., хn - значения y1 = y2 = ... = yn = 0. Очевидно, что многочлен будет иметь вид
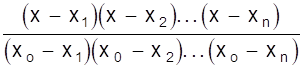 .
.
Здесь при х = хо числитель и знаменатель равны, а при х = х1, х2, ..., хn - числитель равен нулю.
Теперь построим многочлен Fо (х), принимающий в точке хо значение yо и обращающийся в нуль для значений х = х1, х2, ..., хn. Учитывая предыдущее построение можно записать
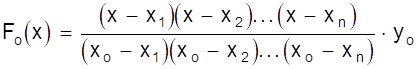 .
.
Теперь можно записать многочлен F (х) для произвольного значения хi ( i = 0, 1, 2, ..., n ) принимающего значения F (хi) = yi, а во всех остальных точках х ¹ хi значение, равное нулю
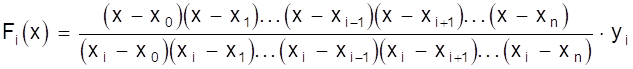 .
.
Как видно из записи, числитель не будет содержать выражения (х - хi), а знаменатель - (хi - хi), т.е. выражений, обращающих числитель и знаменатель в нуль.
Искомый многочлен будет равен сумме
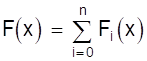 ,
,
т.е. снова в каждой точке хi одно из слагаемых принимает нужное значение yi, а все остальные обращаются в нуль.
В развернутом виде
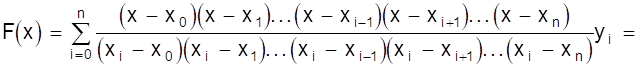
=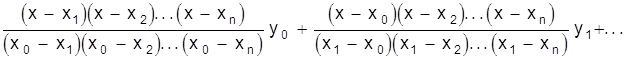
... + 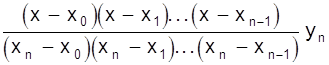 .
.
Полученная формула называется интерполяционной формулой Лагранжа.
Используя формулу Лагранжа запишем многочлен F (х) для разобранного выше примера.
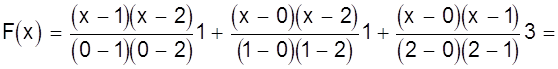
= 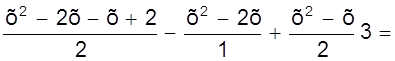
=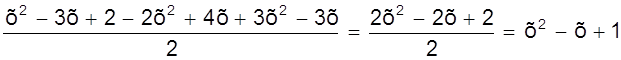 .
.
Получили тоже самое выражение, что и ранее.
Контрольные вопросы
1. Назначение графического метода обработки результатов;
2. Сущность графического метода обработки результатов;
3. Понятие и назначение функциональной шкалы;
4. Выбор масштаба функциональной шкалы;
5. Сущность аппроксимации методом средних;
6. Сущность аппроксимации методом наименьших квадратов;
7. Принципиальное отличие метода интерполирования от метода наименьших квадратов.
4.ОСНОВЫ НОМОГРАФИИ
Номография - слово греческое. Номос - закон, графо - пишу, черчу. В буквальном переводе это слово означает ²черчение закона².
Своей задачей номография ставит построение специальных графиков - номограмм, служащих для решения различных уравнений. Номограммы дают возможность компактно представлять функции многих переменных и таблицы с несколькими входами. На номограммах можно решать некоторые трансцендентные уравнения и системы таких уравнений. Номограммы можно применять не только для вычислительных целей, но и для исследования положенных в их основу функциональных зависимостей.
Наглядность представления различных закономерностей и простота использования номограмм при достаточно высокой точности результата обеспечивают широкое использование номограмм в различных областях техники.
В основе номограмм лежит понятие функциональной шкалы ( см. выше ). На основе функциональных шкал создаются не только номограммы, но и различные вычислительные средства: универсальные вычислительные номограммы, логарифмические линейки и т.п.
В данной главе излагается один из возможных видов номограмм - номограммы в декартовой системе координат, имеющие достаточно широкое использование в машиностроении.
4.1. Номограммы в декартовой системе координат
В разделах 3.1., 3.2. описана процедура построения графиков для функции одного переменного. При этом на графике получается одна линия ( прямая или кривая ).
Если же изучаемая функция зависит от двух переменных
Z = ¦ (х, y),
то придавая в этом уравнении, например, параметру y ряд частных ( постоянных ) значений y1, y2, ..., yn можно, как и для функции одного переменного, построить зависимости
Z = ¦ (х, y1);
Z = ¦ (х, y2);
...................
Z = ¦ (х, yn).
Получим систему кривых ( в частном случае прямых ), называемых номограммой из ²помеченных² линий, т.к. каждая линия помечается соответствующим значением yi.
Пример. При исследовании процесса фрезерования было установлено, что наиболее целесообразно величину радиального биения смежных зубьев фрезы назначать по условию обеспечения участия в процессе резания всех зубьев фрезы. Аналитически это условие выражается уравнением
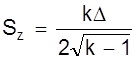 ,
,
где Sz - расчетная величина подачи на зуб, мм/зуб;
k = ![]() - параметр
операции;
- параметр
операции;
D - диаметр фрезы, мм;
t - глубина резания, мм;
D - величина биения смежных зубьев фрезы, мм.
Как видно, Sz = ¦ (k, D) является функцией двух параметров. Здесь можно
отметить, что, фактически Sz
= ¦ (D, t, D), т.е. функцией
трех параметров, но два параметра (D, t) заменены одним - k = ![]() , легко определяемым и уменьшающим количество
переменных. Данный прием широко используется в номографии.
, легко определяемым и уменьшающим количество
переменных. Данный прием широко используется в номографии.
Теперь необходимо определиться с осями и помеченным параметром. В качестве оси ординат, в соответствии с функциональной зависимостью, рационально принять Sz. В качестве же оси абсцисс можно принять либо k, либо D. Если в качестве оси ординат принять k ( а помеченным параметром Di ), то зависимость
Sz = ¦ (k, Di)
будет получаться
криволинейной, в соответствии с закономерностью 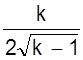 .
Проще строить и использовать прямолинейные графики при равномерных шкалах.
Поэтому стараются номограммы строить на основе прямых линий. Поэтому лучше
будет строить номограмму из помеченных линий вида
.
Проще строить и использовать прямолинейные графики при равномерных шкалах.
Поэтому стараются номограммы строить на основе прямых линий. Поэтому лучше
будет строить номограмму из помеченных линий вида
Sz = ¦ (D, Ki),
где 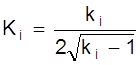 .
.
Теперь выбираем масштаб построения и диапазоны изменения переменных. С учетом условий процесса фрезерования принимаем D £ 0,08 мм; Sz £ 0,20 мм/зуб. Параметр k изменяем дискретно k = 2; 5; 10; 20; 30; 40; 50. Так как зависимость Sz = ¦ (D, Ki) является прямой линией, проходящей через начало координат, то для построения графиков достаточно вычислить только одно значение Sz при каком - либо значении D. Например, для k = 2, при D = 0,06 мм имеем
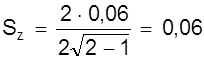 (
мм/зуб ).
(
мм/зуб ).
Теперь через точки ( 0; 0 ) и ( 0,06; 0,06 ) можно провести прямую линию и пометить ее параметр k = 2. Аналогично проводятся и другие линии ( рис. 13 ). На номограмме наносится линия, показывающая порядок ее использования.
Рис. 13. Номограмма определения допустимой величины
радиального биения смежных зубьев фрезы.
4.2. Составные номограммы с помеченными линиями
Номограмму в одной четверти можно построить для функции двух переменных. При большем числе переменных это сделать уже нельзя. В этом случае используют составные номограммы. Идею построения рассмотрим сначала в общем виде.
Пусть нам дано уравнение в неявном виде с четырьмя переменными
¦ (х, y, z, h) = 0.
Допустим, что его можно привести к виду
¦1(х, y) = ¦2 (z, h),
т.е. можно разделить переменные. Положим
¦1 (х, y) = g;
¦2 (z, h) = g.
Мы получим два уравнения, зависящих от двух переменных. Каждое из этих уравнений можно номографировать, как описано выше. Обеспечив отсчет величины g на одинаковой функциональной шкале, можно обойтись и без численных значений g ( если они нас не интересуют по условиям решаемой задачи ). Схематически такая номограмма приведена на рис. 14.
Рис. 14. Схема номограммы с помеченными линиями
с четырьмя переменными
Аналогично поступают и с уравнениями с большим числом переменных, которое будет приводить к увеличению числа общих шкал и большему числу четвертей построения номограммы. Нужно только иметь в виду, что не всякое уравнение допускает разложение на несколько уравнений с двумя переменными и, следовательно, не всякое уравнение удается таким образом номографировать.
Рассмотрим реальный пример построения составной номограммы.
При исследовании процесса фрезерования было установлено, что сила резания при фрезеровании узких поверхностей приобретает характер повторяющихся импульсов не гармонической формы. И возмущение технологической системы осуществляется не на одной, а в бесконечном диапазоне частот. Наиболее опасно воздействие первых трех гармоник, несущих значительно больше энергии возмущения, чем все другие. Распределение энергии по этим трем гармоникам осуществляется в зависимости от отношения фронтов нарастания и спада силы в импульсе. Это отношение можно характеризовать отношением углов контакта фрезы (j) и зуба фрезы (y) с заготовкой. Причем всегда j ³ y.
Для наглядного представления и определения характера распределения энергии по трем гармоникам в зависимости от условий операции построим номограмму.
В одной из четвертей первоначально отражается характер распределения энергии по гармоникам возмущения в зависимости от j/y (рис. 15). Эти зависимости построены из результатов исследований, которые здесь не отражаются. Коэффициент Х2 характеризует ²удельный вес² энергии данной гармоники в общем силовом возмущении. Диапазон j/y = 1...9.
Теперь отношение j/y раскрываем в параметрах инструмента и операции
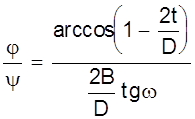 .
.
Видно, что здесь четыре переменных величины: D, t, B, w.
Введем промежуточную ось С и построим номограмму из помеченных линий для одной из переменных величин, а именно Вi
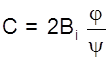 .
.
Видно, что это уравнения прямых линий, проходящих через начало координат. Задаваясь одним значением j/y и Вi можно провести ее график. Например, при j/y = 5, Вi = 5 получим С = 2×5×5 = 50. Аналогично поступаем для Вi = 10; 15; 20.
Далее вводим следующую промежуточную ось ( и соответственно переменную ) L = C ×tg wi. Задаваясь величинами угла wi и С можно определить положение помеченных линий. Например, при w = 45°, С = 50
L = 50×tg 45° =50. Àíàëîãè÷íî ïîñòóïàåì è äëÿ äðóãèõ óãëîâ wi = 15°; 30°; 60°; 75°. Проводим прямые линии через начало системы координат и помечаем значение угла wi каждой линии.
Таким образом осталась одна взаимосвязь параметров
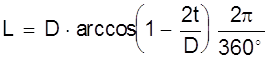 .
.
Здесь необходимо определиться с параметром, направленном по оси и ²помеченным² параметром. В любом случае зависимость нелинейная. Кроме того, глубина резания является задаваемым параметром и его лучше взять в качестве ²помеченного² параметра. Для построения помеченных линий нужно определить несколько координат каждой линии.
Рассмотрим ²помеченную² линию t = 5 мм. В качестве переменного параметра принимаем диаметр фрезы D. При D = 25; 50; 100; 150; 200 мм соответственно имеем
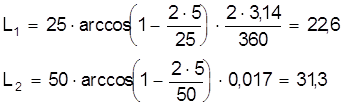
![]()
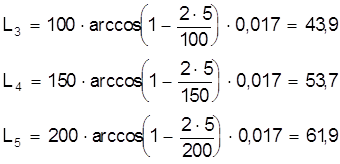
По найденным точкам строится линия для t = 5 мм. Аналогично поступают и для других значений t.
На рис. 15 показана построенная номограмма. Указаны промежуточные оси С, L, которые при использовании номограммы не нужны и могут не указываться, указаны и частные зависимости для каждой четверти номограммы.
Полученная номограмма наглядно показывает, что распределение энергии по гармоникам возмущения технологической системы определяется условиями операции, изменяя которые можно воздействовать на возмущение технологической системы.
Для исключения резонансных явлений необходимо знать спектр собственных частот системы и согласовывать условия операции с их значениями, уменьшая количество энергии на ²резонансной² частоте. Эти данные, как правило, отсутствуют. Поэтому используя номограмму можно скорректировать условия операции. Для этого по известным параметрам фрезы, которая показала неудовлетворительные результаты, и элементам режима резания необходимо определить распределение энергии по гармоникам возмущения и выбрать другое распределение. Так как глубину резания и ширину фрезерования изменять, как правило, невозможно, а изменение угла наклона режущей кромки часто нецелесообразно по условиям
Рис. 15. Номограмма распределения энергии по гармоникам
возмущения и условия операции
стойкости инструмента, то новое распределение энергии можно получить изменив диаметр фрезы ( в большую или меньшую сторону по сравнению с первоначальным ). При этом необходимо сохранить прежним относительное число зубьев ( z/D) и скорость резания, так как число оборотов и зубьев фрезы играют самостоятельную роль в определении частотного диапазона возмущения (inz).
Как видно из изложенного, номограмма может существенно помогать в управлении процессом резания, на основе заложенных в нее функциональных зависимостей.
Контрольные вопросы
1. Сущность и назначение номографии;
2. Функцию какого числа переменных можно отразить в одной четверти декартовой системы координат ?
3. Понятие номограммы из ²помеченных² линий;
4. Сущность составной номограммы и промежуточной функциональной шкалы.
5. ТИПОВЫЕ ЗАДАЧИ МАТЕМАТИЧЕСКОЙ ОБРАБОТКИ
ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ
В целях закрепления знаний и получения практических навыков предлагается решить несколько задач, имеющих практическую направленность.
1. При измерении твердости по Роквеллу были получены следующие результаты. Для образца А: 97,0; 98,7; 99,9; 99,5; 97,1; 99,5; 92,0; 100,6; 99,7; 98,0; 98,5; 99,5; 99,7; 99,5; 99,0; 98,5; 99,5; 98,8; 98,5; 99,1; 98,4; 96,6; 97,2; 101,7; 97,2; 98,2; 97,5; 97,7; 99,0; 99,0; 97,5. Для образца В, проверяемого на этом же приборе: 85,6; 87,1; 87,9; 86,9; 85,6; 85,2; 85,5; 85,7; 84,7; 86,4; 80,0; 85,0; 82,0; 86,0; 86,0; 87,3; 84,5; 87,0; 87,3; 85,4; 91,0; 90,0; 90,8; 89,2; 91,0; 90,4; 84,1; 81,7; 87,4; 84,0; 85,2.
Для каждой группы данных определить значение измеряемого параметра, наличие промахов в ряду измерений. Для какой группы измерений результат получен точнее? Выбрав в случайном порядке 1, 4, 9, 16, 25 отсчетов проверить справедливость зависимости точности среднего значения от числа измерений. Построить эмпирические законы интегрального и дифференциального распределений. Подобрать теоретический закон распределения и оценить его соответствие.
2. Отклонения диаметра вала распределены по нормальному закону. Половина значений диаметра лежит в интервале 20 ± 0,1 мм. Отклонения диаметра отверстия также распределены по нормальному закону. Половина всех отклонений отверстия находится в интервале 20 ± 0,05 мм. Полагая, что сборка соединения производится вручную, определите, сколько из 50 валов не подойдет по размеру. Какой номинальный диаметр осевого отверстия ( вместо 20 мм ) следует задать ( при том же законе распределения ), чтобы все 100% деталей подошли друг к другу при ручной сборке.
3. В цехе машиностроительного завода выполняется сложный заказ, с определенной вероятностью возникновения брака. Для обеспечения плана выпуска 100 изделий запущено в производство 110 единиц. Какова вероятность, что заказ будет выполнен если вероятность получения одного изделия 0,9; 0,95 ?
4. При исследовании обрабатываемости одного из конструкционных материалов были получены зависимости периода стойкости зуба фрезы от угла наклона w стружечной канавки.
Результаты приведены в таблице:
| w° | 20 | 30 | 40 | 50 | 60 |
| T, мин | 30 | 60 | 80 | 70 | 50 |
Используя метод наименьших квадратов и параболического интерполирования получить аналитическую зависимость стойкости от угла наклона .
5. С помощью критерия c2 проверьте соответствие числа бракованных деталей за 51 смену пуассоновскому распределению.
|
Число бракованных изделий за одну смену, m |
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|
Число смен с m бракованными изделиями |
3 | 7 | 9 | 12 | 9 | 6 | 3 | 2 | 0 |
6. Известно, что количество бракованных инструментов в партии соответствует закону Пуассона с параметром интенсивности l = 0,5. Определить количество бракованных изделий в партии.
7. Случайная величина х распределена по закону равной вероятности в интервале [ 1; 10 ]. Определите при каком значении х вероятность его нахождения в заданном интервале равна 0,05 и 0,95 ?
8. Случайная величина х подчиняется нормальному закону распределения с параметрами х = 3, s2 = 25. Вычислить вероятности Р ( Х ³ 10 ), Р ( -2 £ Х £ 8 ), Р ( Х £ -10 ). Дайте графическую иллюстрацию результата.
9. Станок - автомат настроен на выполнение размера 100,1 мм. Разброс размеров деталей подчиняется нормальному закону распределения с дисперсией s2 = 0,25 мм2. Поле допуска на размер детали составляет 100 ± 0,15 мм. Найдите долю брака при проведенной настройке, представьте ее в виде графика от среднеарифметического значения. На какое значение необходимо настроить автомат, чтобы доля брака была минимальной, определите эту долю. Пусть х = 100, s = 0,5. Что окажет большее влияние на увеличение доли брака - сдвиг х на ±0,5 или увеличение s на 0,5 ?
10. При исследовании силы резания в зависимости от глубины резания была измерена главная составляющая силы резания Рz при четырех значениях глубины резания
| t, мм | 1 | 2 | 3 | 4 |
|
Pz, Н |
2300 | 3200 | 4000 | 4600 |
Графическим методом, методом средних и методом наименьших квадратов установить зависимость составляющей силы от глубины резания.
ЛИТЕРАТУРА
1. Теория Вероятностей, М. 1998
2. Гутер Р.С., Овчинский Б.В. Элементы численного анализа и математической обработки результатов опыта. - М.: Физматгиз, 1962. - 356 с.
3. Зайдель А.Н. Ошибки измерения физических величин. - Л.: Наука, 1974. - 108 с.
4. Кассандрова О.Н., Лебедев В.В. Обработка результатов наблюдений. - М.: Наука, 1970. - 104 с.
5. Колесников А.Ф. Основы математической обработки результатов измерений. - Томск: ТГУ, 1963. - 49 с.
6. Плескунин В.И., Воронина Е.Д. Теоретические основы организации и анализа выборочных данных в эксперименте. Учебное пособие. - Л.: ЛЭУ, 1979. - 232 с.
7. Румшинский Л.З. Математическая обработка результатов эксперимента. Справочное руководство. - М.: Наука, 1971. - 192 с.
8. Рыжов Э.В., Горленко О.А. Математические методы в технологических исследованиях. - Киев: Наук. думка, 1990. - 184 с.
9. Сухов А.Н. Математическая обработка результатов измерений. Учебное пособие. - М.: МИСИ, 1982. - 89 с.
10. Чкалова О.Н. Основы научных исследований. - Киев: Вища школа, 1978. - 120 с.
ОГЛАВЛЕНИЕ
ВВЕДЕНИЕ...........................................................................................3
1. ОШИБКИ ИЗМЕРЕНИЙ.......................................................................4
1.1. Цели математической обработки результатов эксперимента .............
1.2. Виды измерений и причины ошибок.................................................5
1.3. Типы ошибок измерения...................................................................5
1.4. Свойства случайных ошибок.............................................................6
1.5. Наиболее вероятное значение измеряемой величины........................8
1.6. Оценка точности измерений.............................................................9
1.7. Понятие доверительного интервала и доверительной вероятности...11
1.8. Обнаружение промахов..................................................................13
1.9. Ошибки косвенных измерений........................................................14
1.10. Правила округления чисел............................................................16
1.11. Порядок обработки результатов измерений...................................17
1.12. Обработка результатов измерений диаметра цилиндра...................18
Контрольные вопросы....................................................................22
2. ЗАКОНЫ РАСПРЕДЕЛЕНИЯ СЛУЧАЙНЫХ ВЕЛИЧИН.....................22
2.1. Виды случайных величин и законы их распределения........................
2.2. Числовые характеристики случайных величин, заданных своими
распределениями............................................................................25
2.3. Основные дискретные и непрерывные законы распределения..........27
2.4. Понятие статистической гипотезы и статистического критерия.......33
2.5. Вероятность ошибок первого и второго рода...................................34
2.6. Проверка гипотезы вида закона распределения вероятностей...........36
Контрольные вопросы.....................................................................38
3. НАХОЖДЕНИЕ ИНТЕРПОЛИРУЮЩИХ КРИВЫХ.............................38
3.1. Графический метод обработки результатов......................................38
3.2. Функциональные шкалы и их применение.......................................40
3.3. Аналитические методы обработки результатов................................42
3.3.1. Способ средней.......................................................................43
3.3.2. Метод наименьших квадратов..................................................44
3.3.3. Интерполирование функций....................................................48
3.3.4. Параболическое интерполирование..........................................48
Контрольные вопросы.....................................................................50
4. ОСНОВЫ НОМОГРАФИИ..................................................................51
4.1. Номограммы в декартовой системе координат....................................
4.2. Составные номограммы с помеченными линиями............................53
Контрольные вопросы.....................................................................58
5. ТИПОВЫЕ ЗАДАЧИ МАТЕМАТИЧЕСКОЙ ОБРАБОТКИ ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ......................................................................58
ЛИТЕРАТУРА......................................................................................61
![]()
